Difinity Platform Guide
Complete guide for implementing and managing your enterprise AI governance platform.
Platform Documentation
Difinity is an enterprise AI governance platform that gives organisations complete control over their AI workloads — from model selection and cost management to regulatory compliance and audit trails. This documentation covers the platform's capabilities and the Flow API integration reference.
System Overview
Difinity consists of three integrated components:
- Difinity Hub — the web-based management console where administrators configure AI use cases, manage users and applications, monitor compliance, and review costs and audit data.
- Difinity Flow API — a unified AI gateway that routes requests to multiple AI providers (OpenAI, Anthropic, Google/Gemini, DeepSeek, Grok) while enforcing all governance policies defined in Hub.
- Difinity.ai — the enterprise platform combining both, delivering a coherent governance experience across configuration and execution.
Core Value Propositions
| Value | Description |
|---|---|
| Data Sovereignty | All organisational data remains within your infrastructure |
| Complete Governance | Granular control over AI workloads, routing, and usage |
| Cost Optimisation | Intelligent routing and markup management across providers |
| Regulatory Compliance | Automated EU AI Act and ISO 42001 compliance tracking |
| Unified Management | Single platform across multiple providers and models |
How the Components Work Together
Hub is where policy is defined: use case configuration, compliance rules, PII handling settings, user permissions, and API token issuance. Flow is where policy is enforced: every AI request passes through Flow, which applies the rules from Hub before and after calling the underlying provider. The result is that governance configuration and API execution are always in sync — changing a threshold in Hub takes effect immediately for all subsequent API calls.
Getting Started
Prerequisites
- Access to a Difinity Hub instance with appropriate user permissions
- An application registered in Hub with at least one assigned use case
- An API token generated for that application (from the Applications page)
- The use case ID for the workflow you intend to call
First Steps
- Sign in to Difinity Hub and navigate to Applications to register your application and generate an API token.
- Note the use case ID for the workflow your application will use (visible in the Use Cases list).
- Exchange the Hub API token for a Flow JWT by calling
POST /api/v1/auth/exchange. - Include the Flow JWT and use case ID as headers on all subsequent Flow API calls.
Difinity Hub
Authentication
Hub uses email and password authentication. The sign-in page accepts organisational email credentials, with a password reset flow available via the "Forgot password" link.
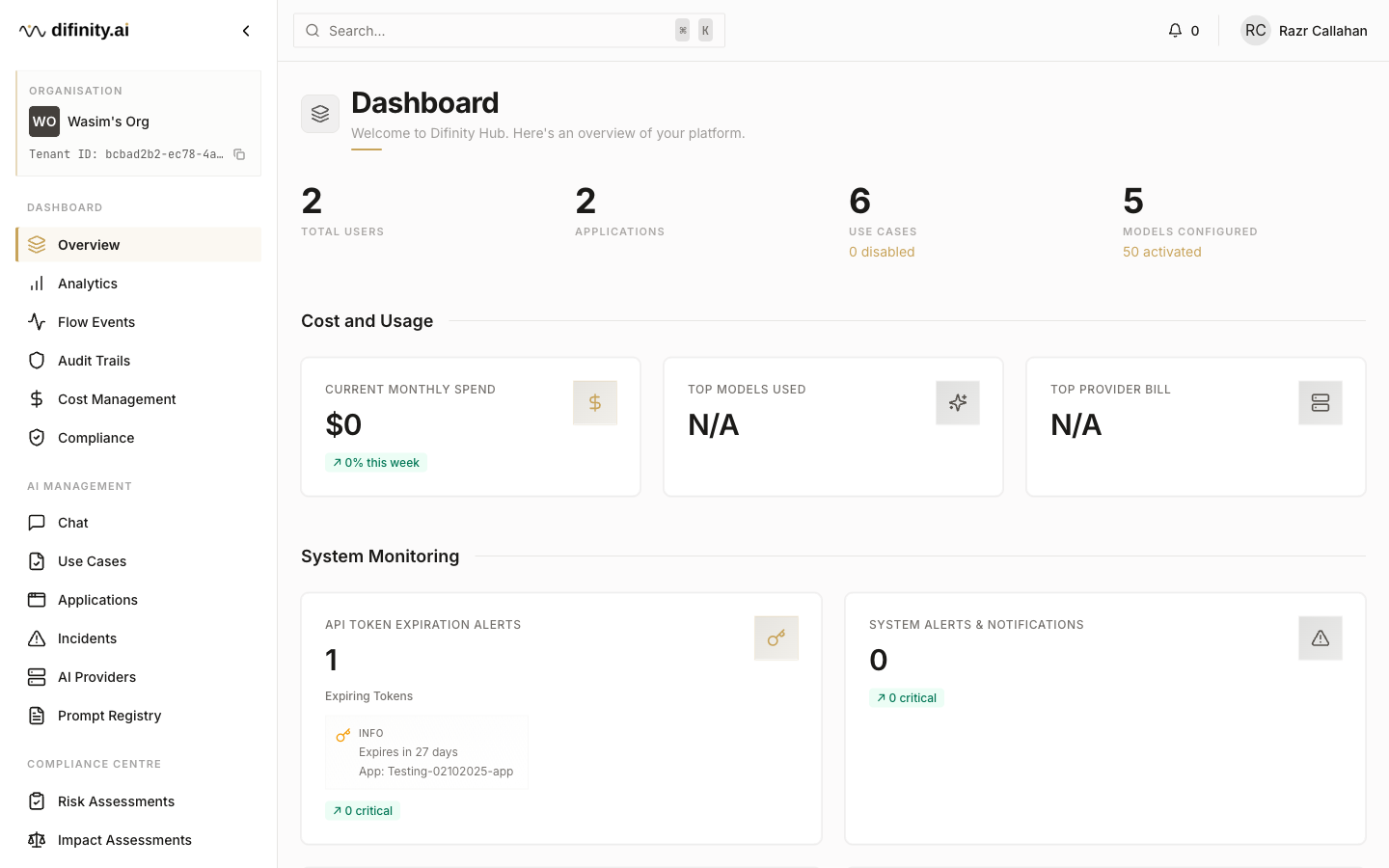
Dashboard Overview
The dashboard provides a real-time summary of platform health and activity. It surfaces key counters (total users, registered applications, configured use cases, available models), cost and usage trends, system monitoring status, and a compliance snapshot showing current posture across active use cases.
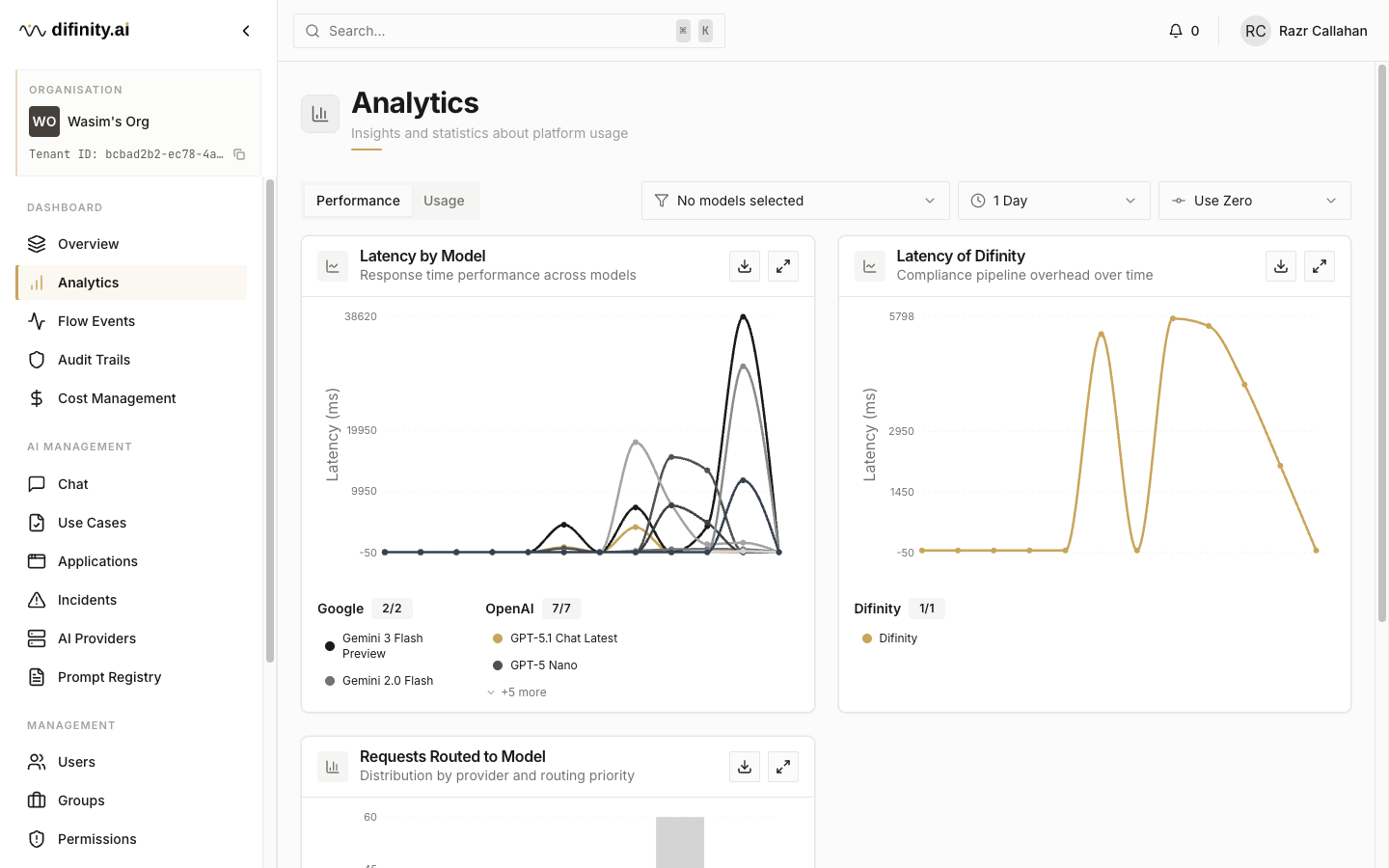
Analytics
The Analytics section provides visibility into how AI is being used across the platform, with two tabs:
- Performance — latency by model, Difinity's own processing latency, and request volume routed to each model.
- Usage — token consumption broken down by model, application, and use case.
Global filters for model, time range, and zero-usage inclusion apply across both tabs. Every chart supports CSV export and full-screen viewing for detailed analysis.
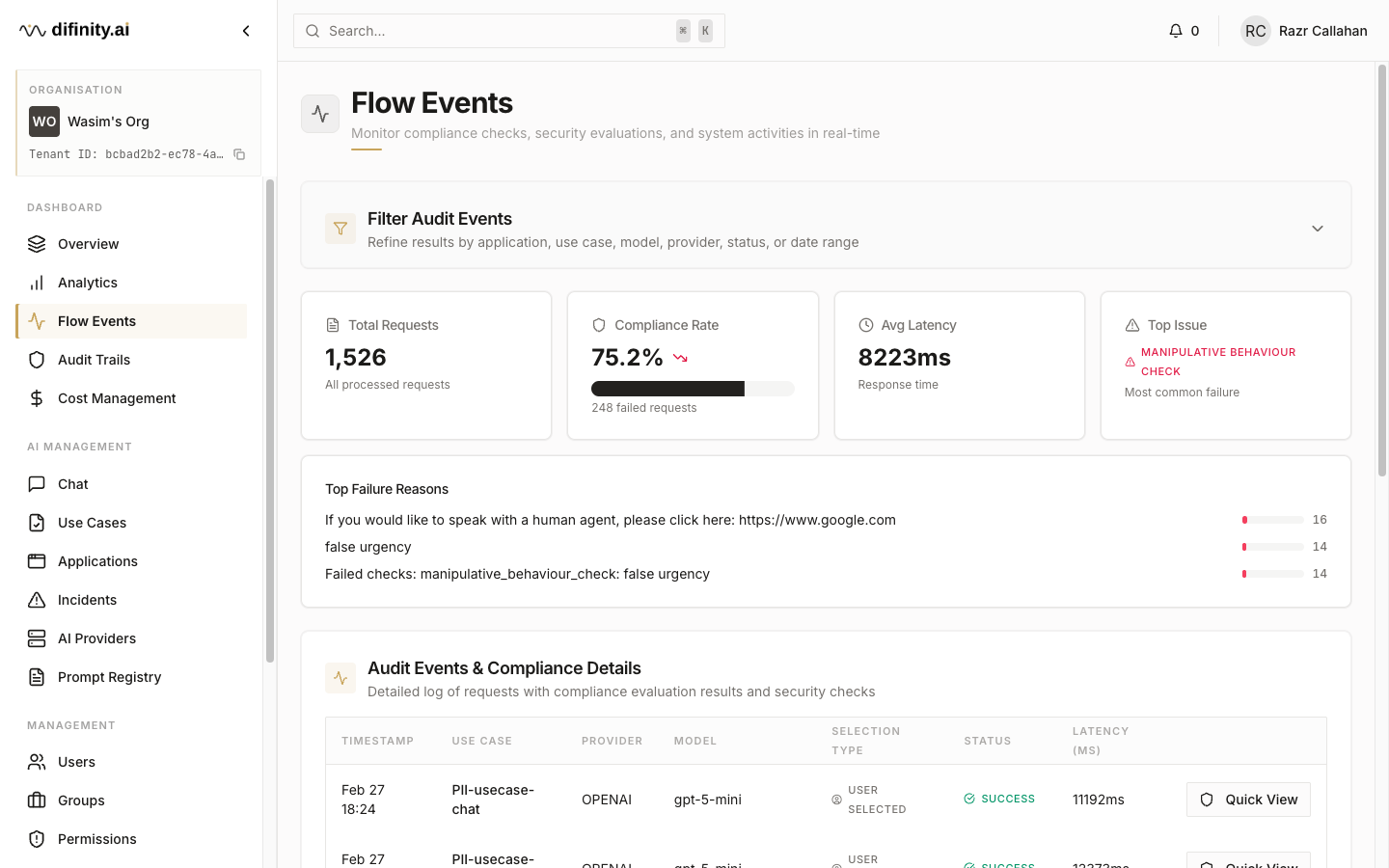
Flow Events
Flow Events is the real-time monitoring view for all AI requests processed through the platform. It is the primary tool for operational observability and compliance incident investigation.
The summary bar shows total requests, compliance pass rate, average latency, and the top issue type detected. A breakdown of top failure reasons provides quick orientation before drilling into individual events.
The audit events table is filterable by use case, application, user, model, provider, compliance status, and date range. Selecting an event opens a detail view with the full evaluation results: PII detection findings, per-check compliance results, protection configuration applied, and the threshold settings active at the time of the request.
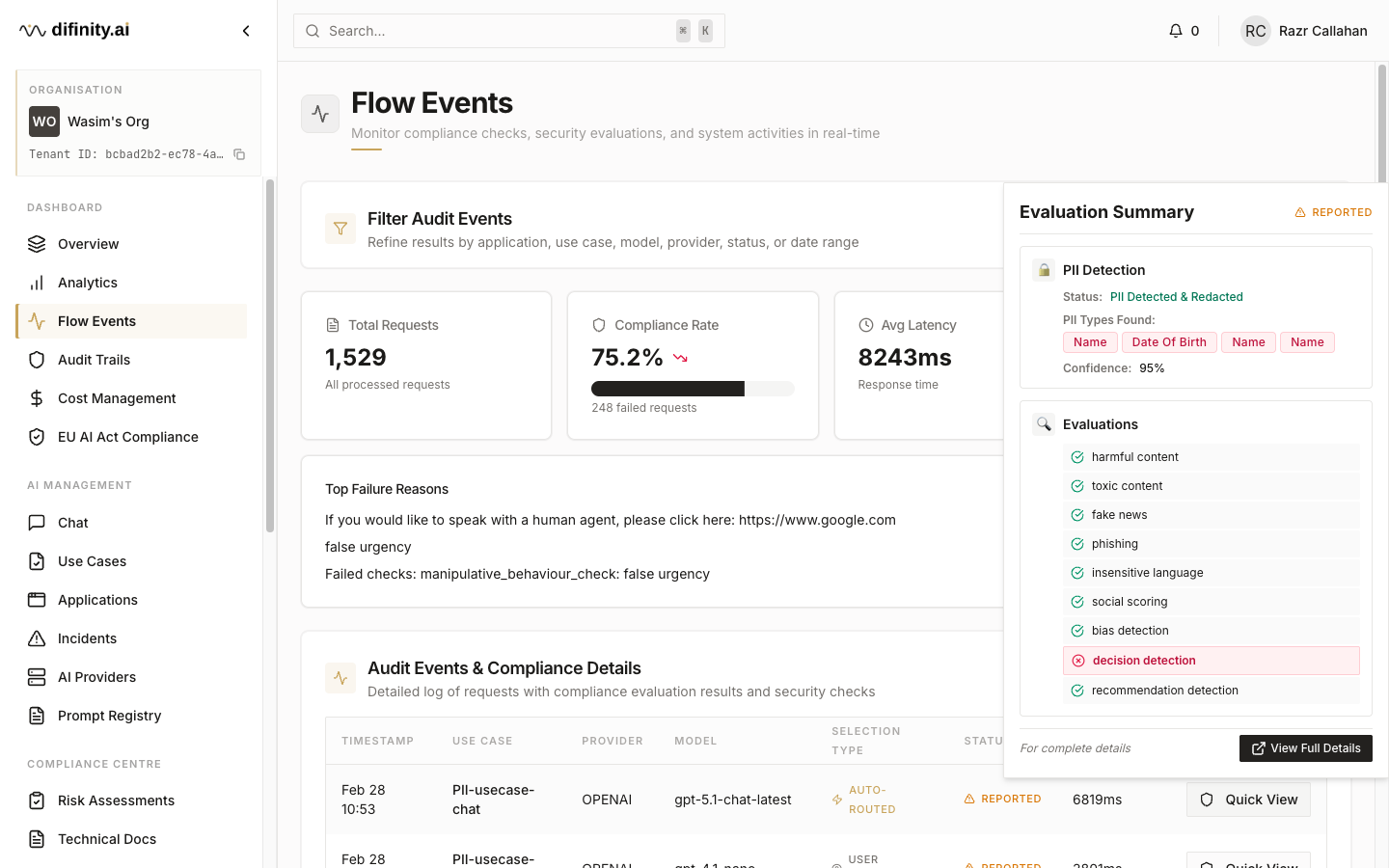
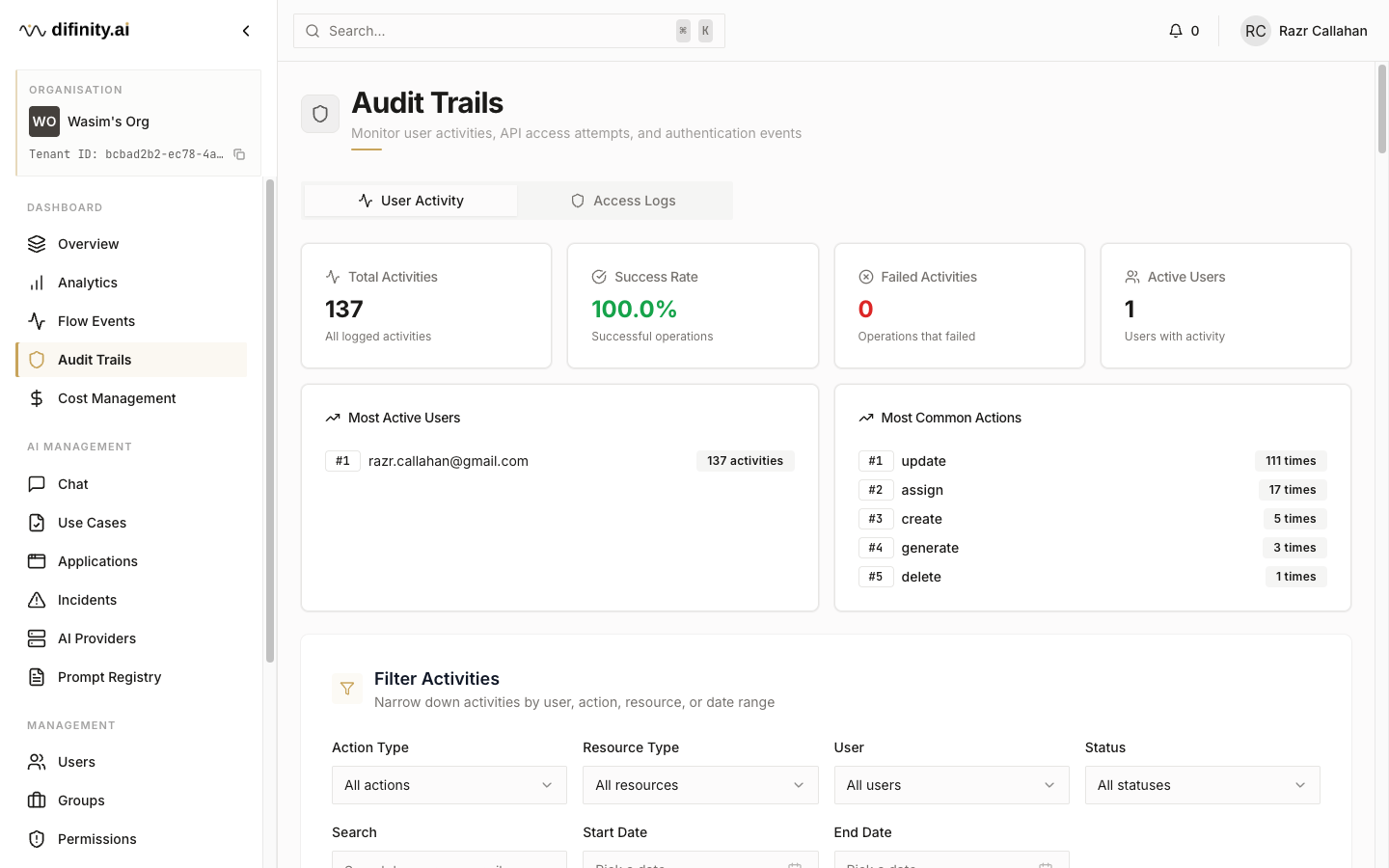
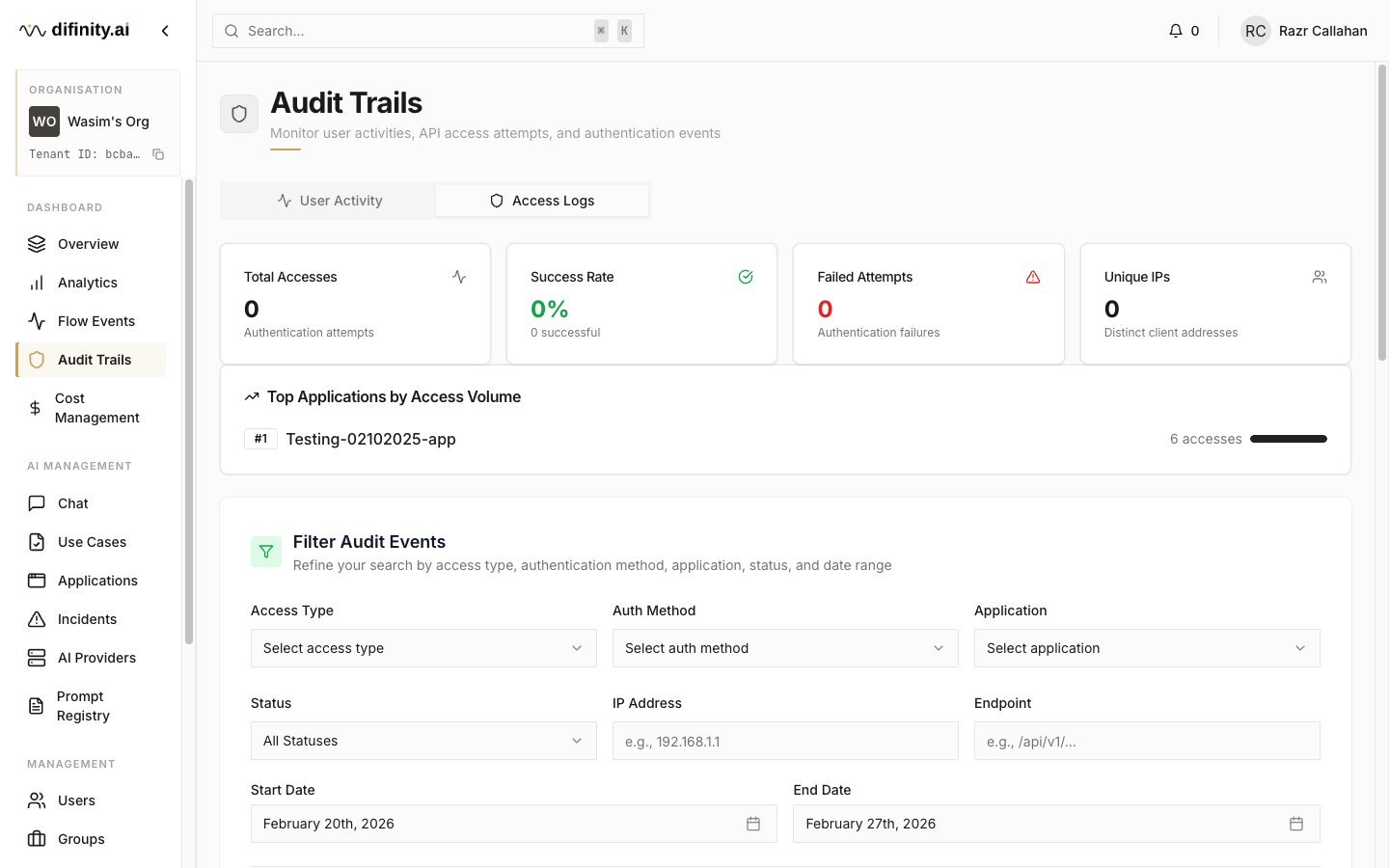
Audit Trails
Audit Trails provides two distinct logs:
- User Activity — every action taken within Difinity Hub, including who made changes, to what, and when. Summary stats, activity insights (most active users, common action types), and a filterable activity log are included.
- Access Logs — API authentication and access events, showing total accesses, success rate, failed attempts, unique source IPs, and top applications by request volume.
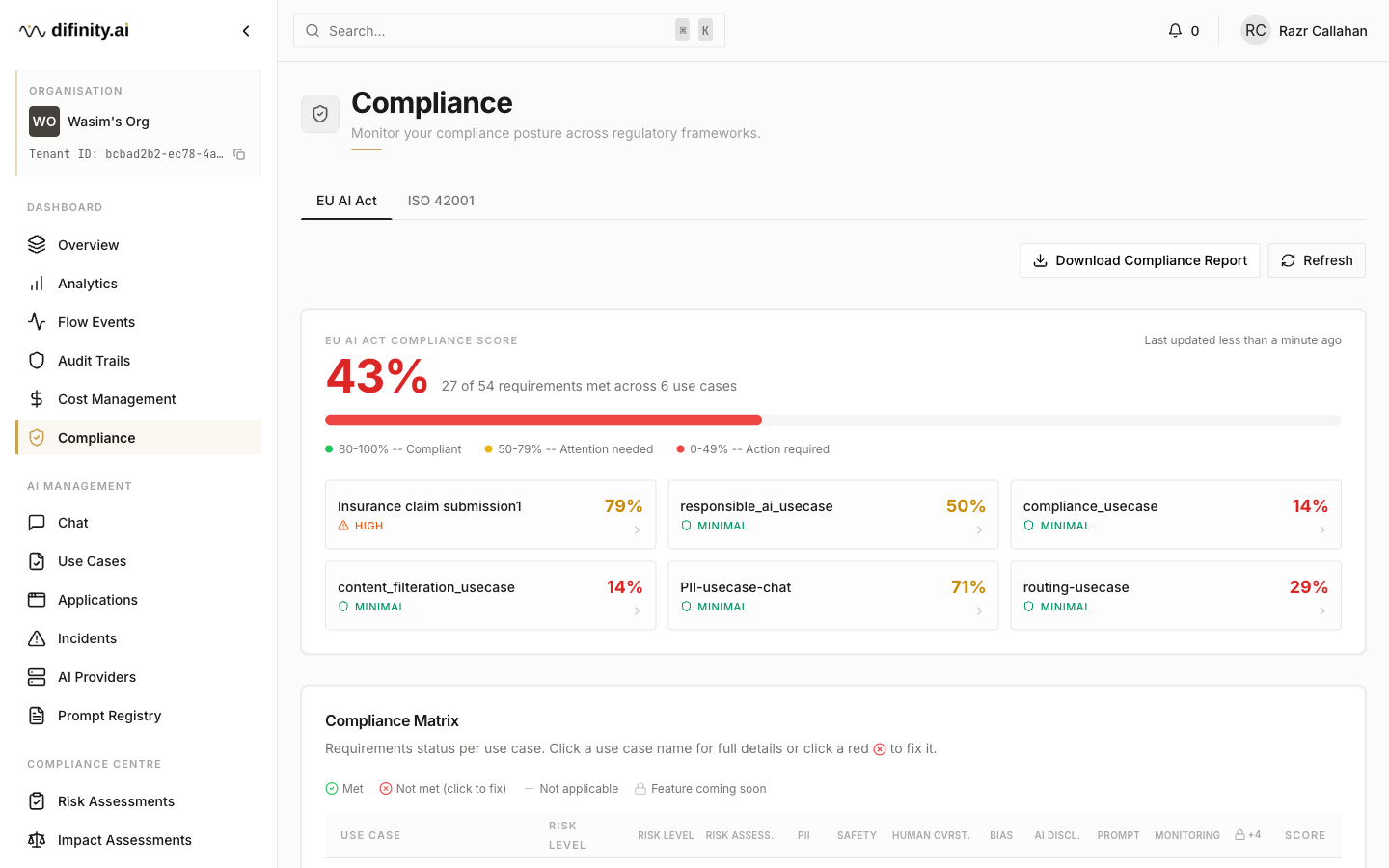
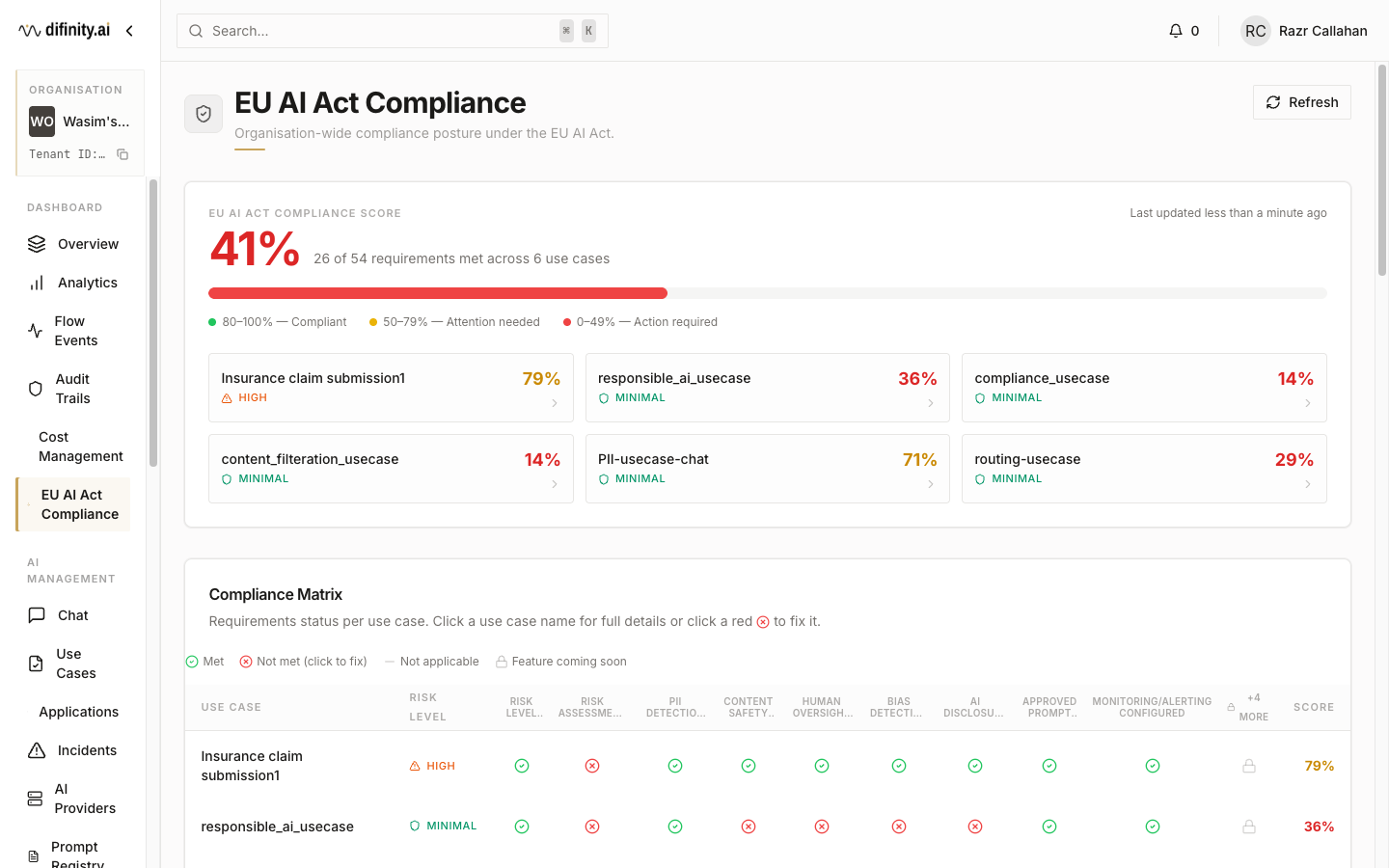
Compliance Dashboard
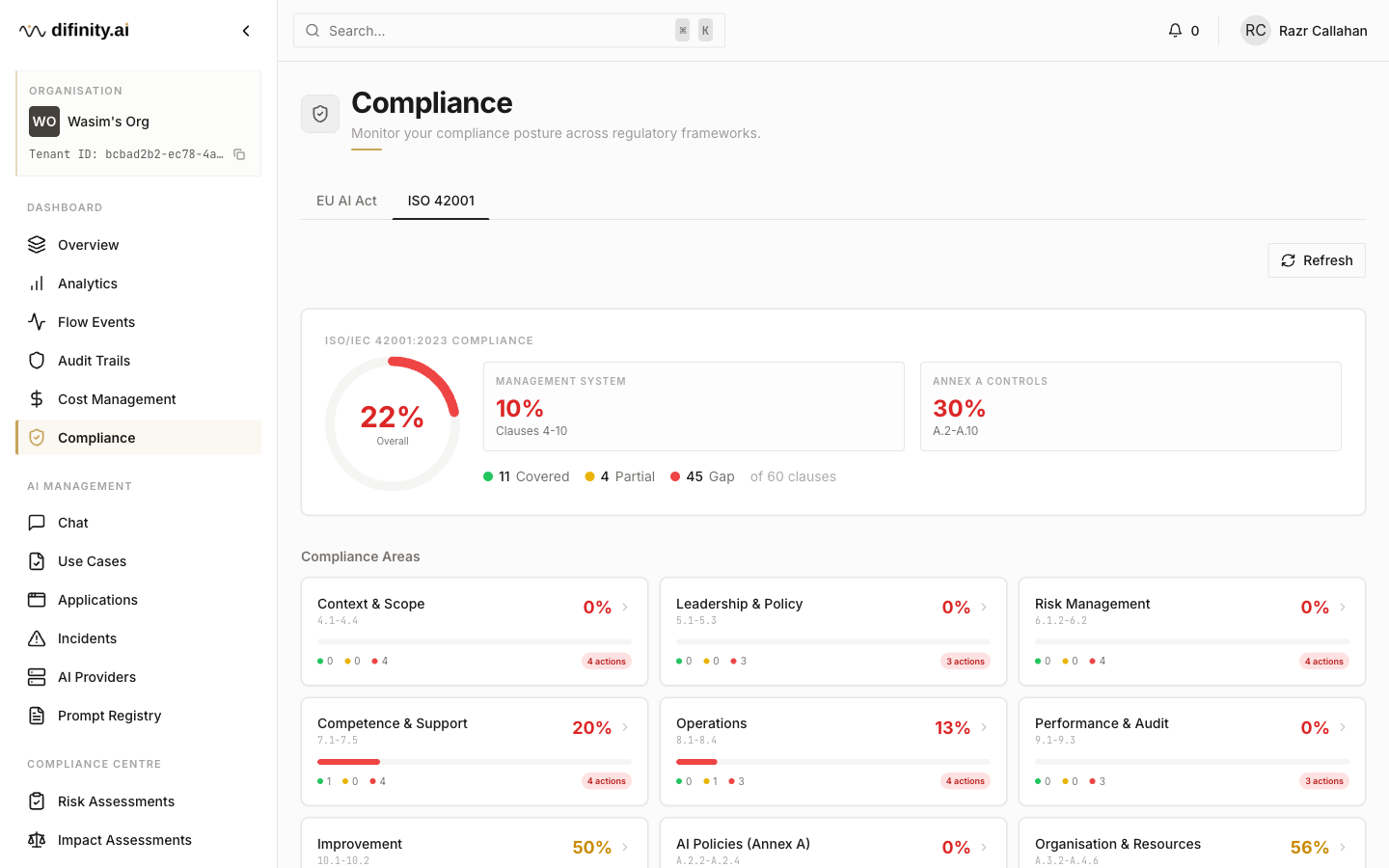
The Compliance Dashboard provides a unified view of regulatory posture across EU AI Act and ISO 42001 frameworks.
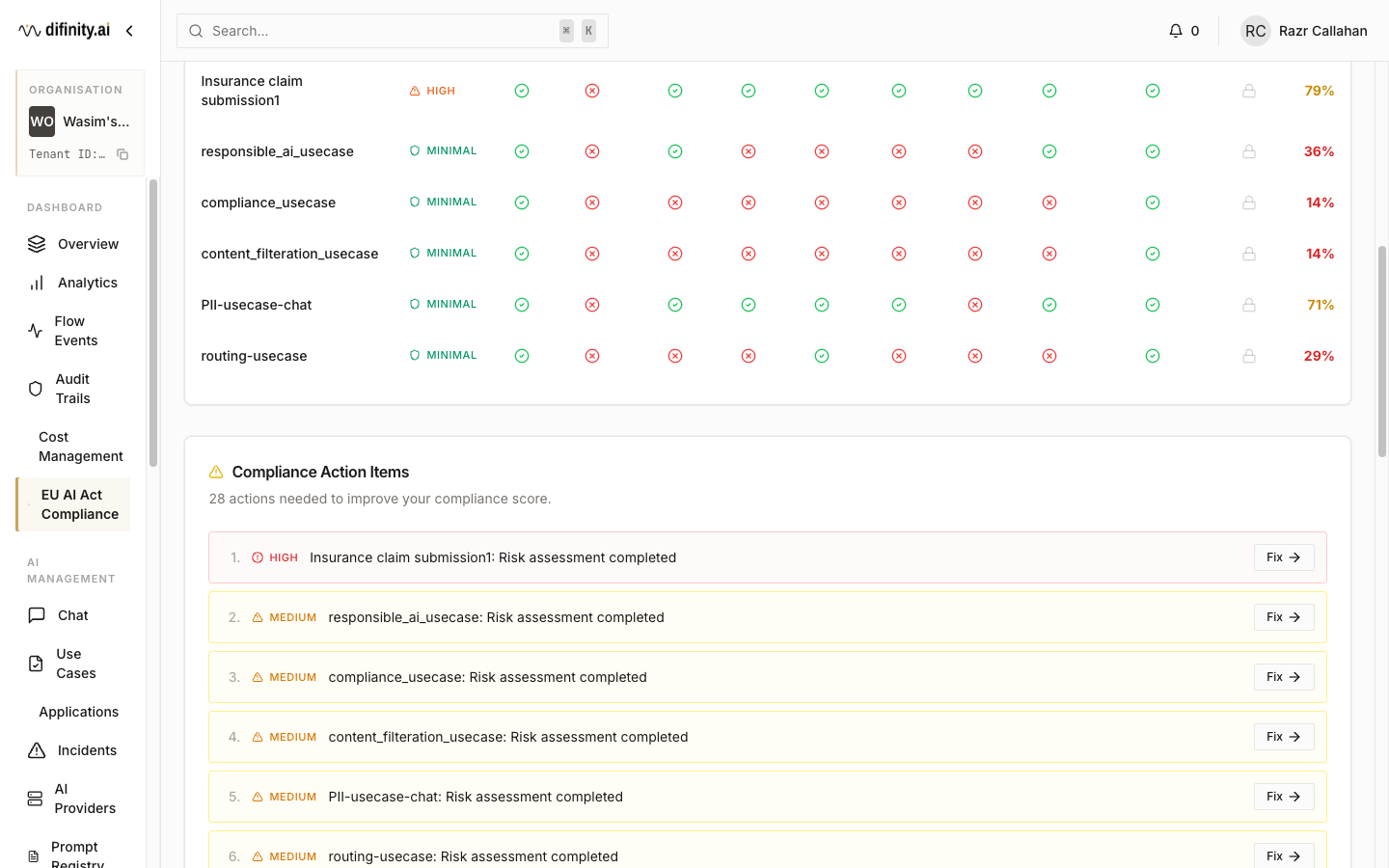
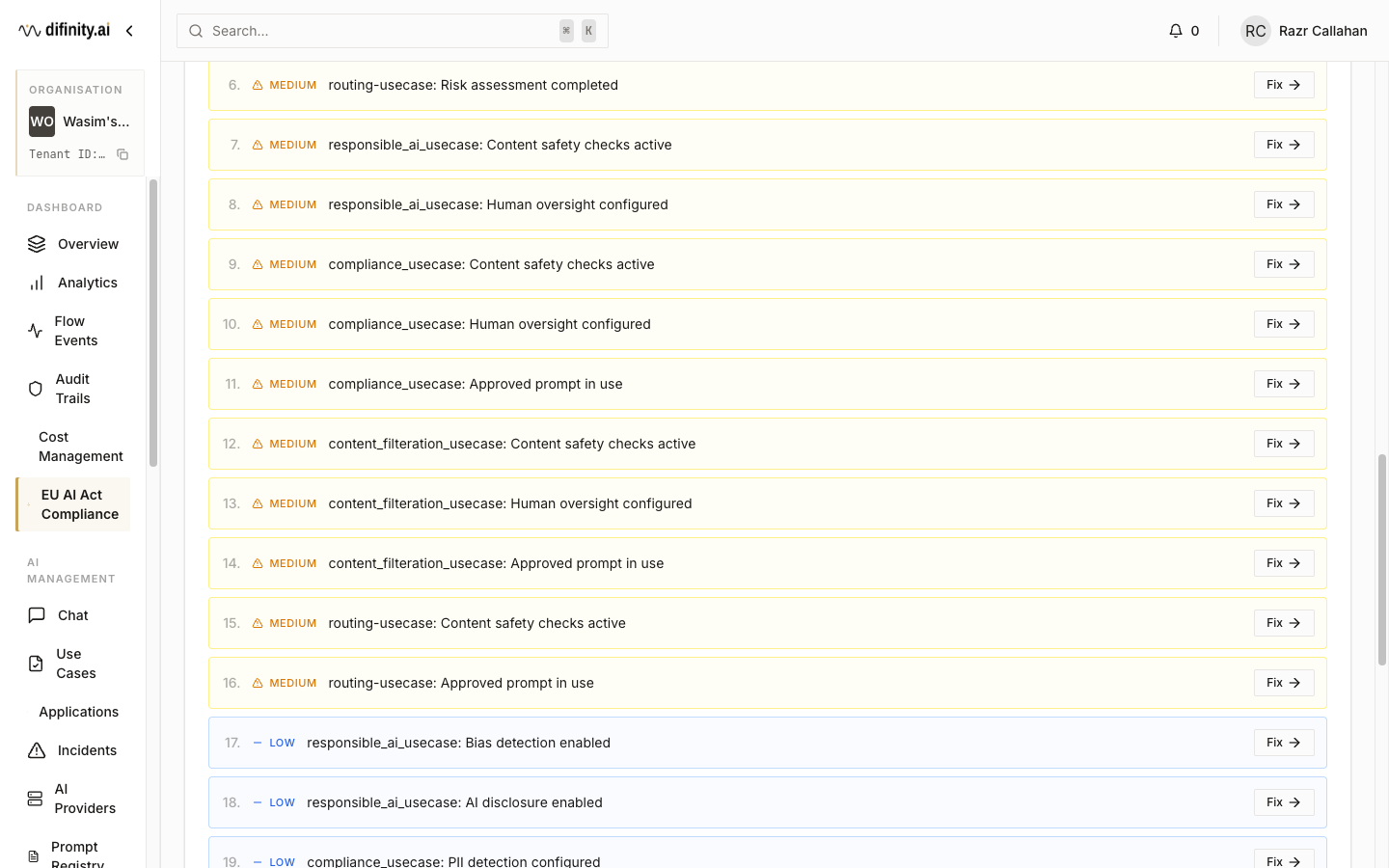
EU AI Act tab displays an overall compliance score (0–100%, colour-coded by band), per-use-case compliance cards, and a detailed compliance matrix covering 15+ requirements per use case. Each requirement is marked with a checkmark (met), X (gap), dash (not applicable), or lock (requires action). An action items panel lists prioritised remediation steps with direct "Fix" links.
ISO 42001 tab displays a circular ring gauge score alongside 15 compliance area cards covering Clauses 4–10 and Annex A.2–A.10. A detailed matrix shows status for each control as COVERED, PARTIAL, GAP, or NOT_SCORED. Action items are generated automatically from the gap analysis, with support for manually added items.
Cost Management
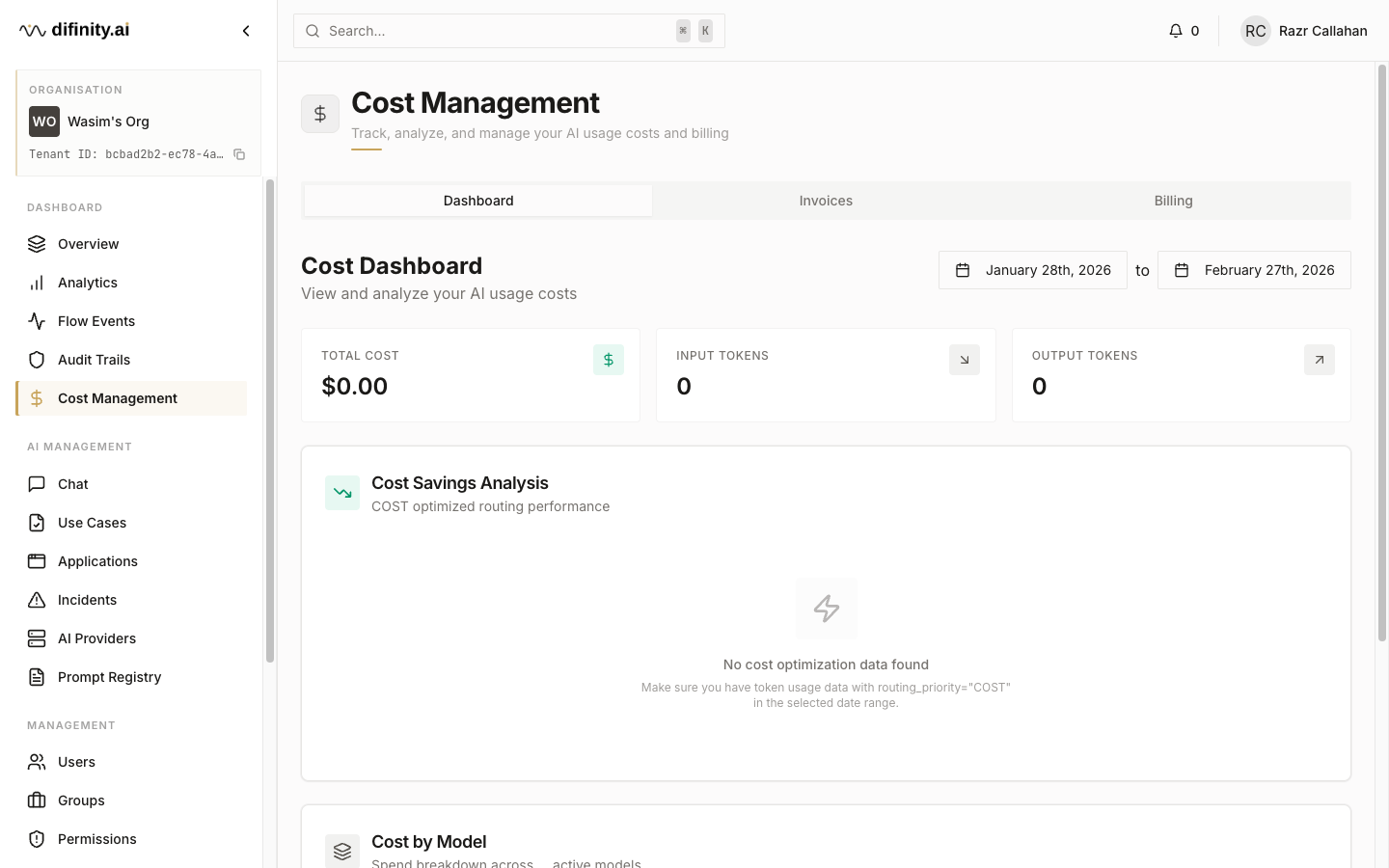
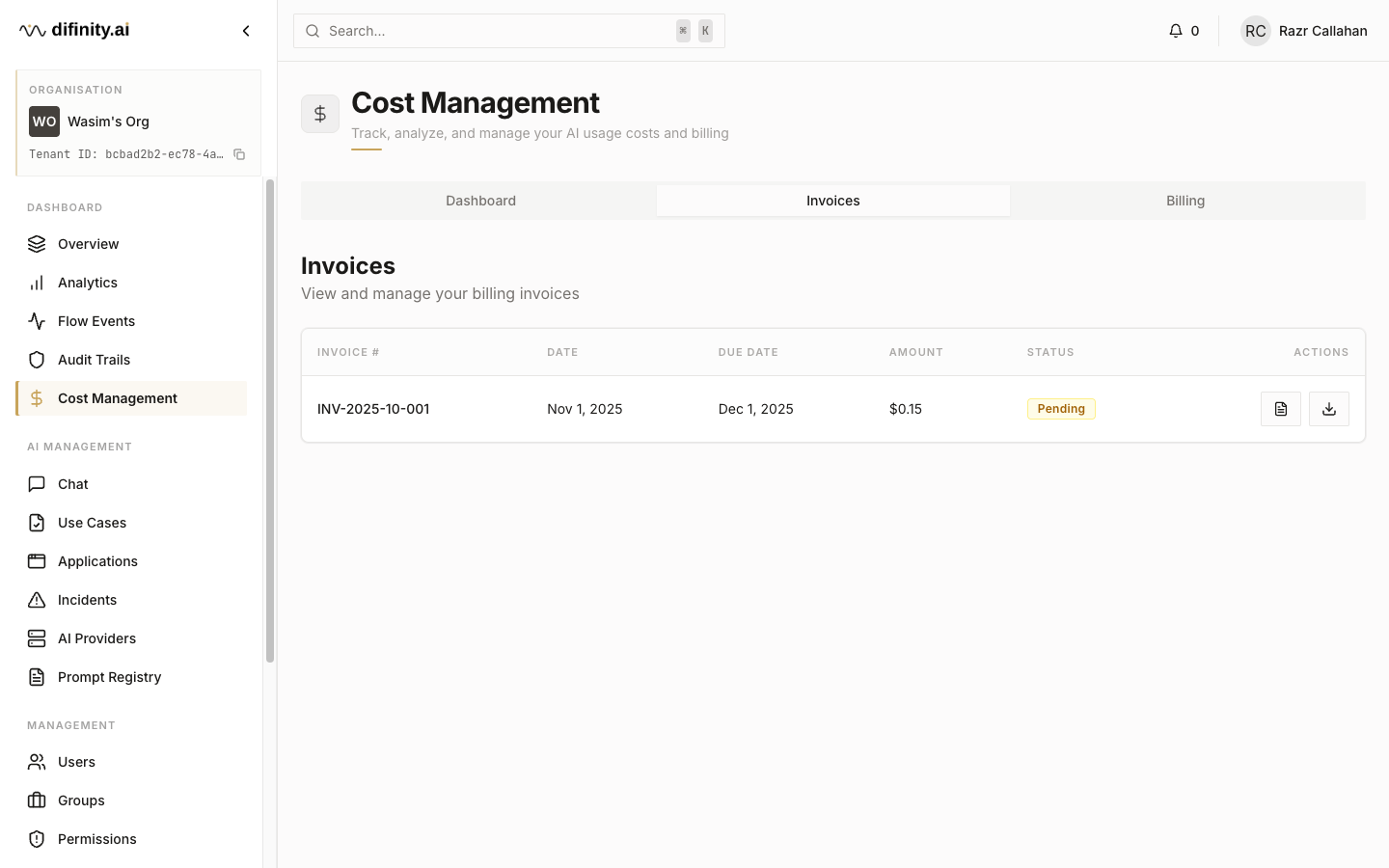
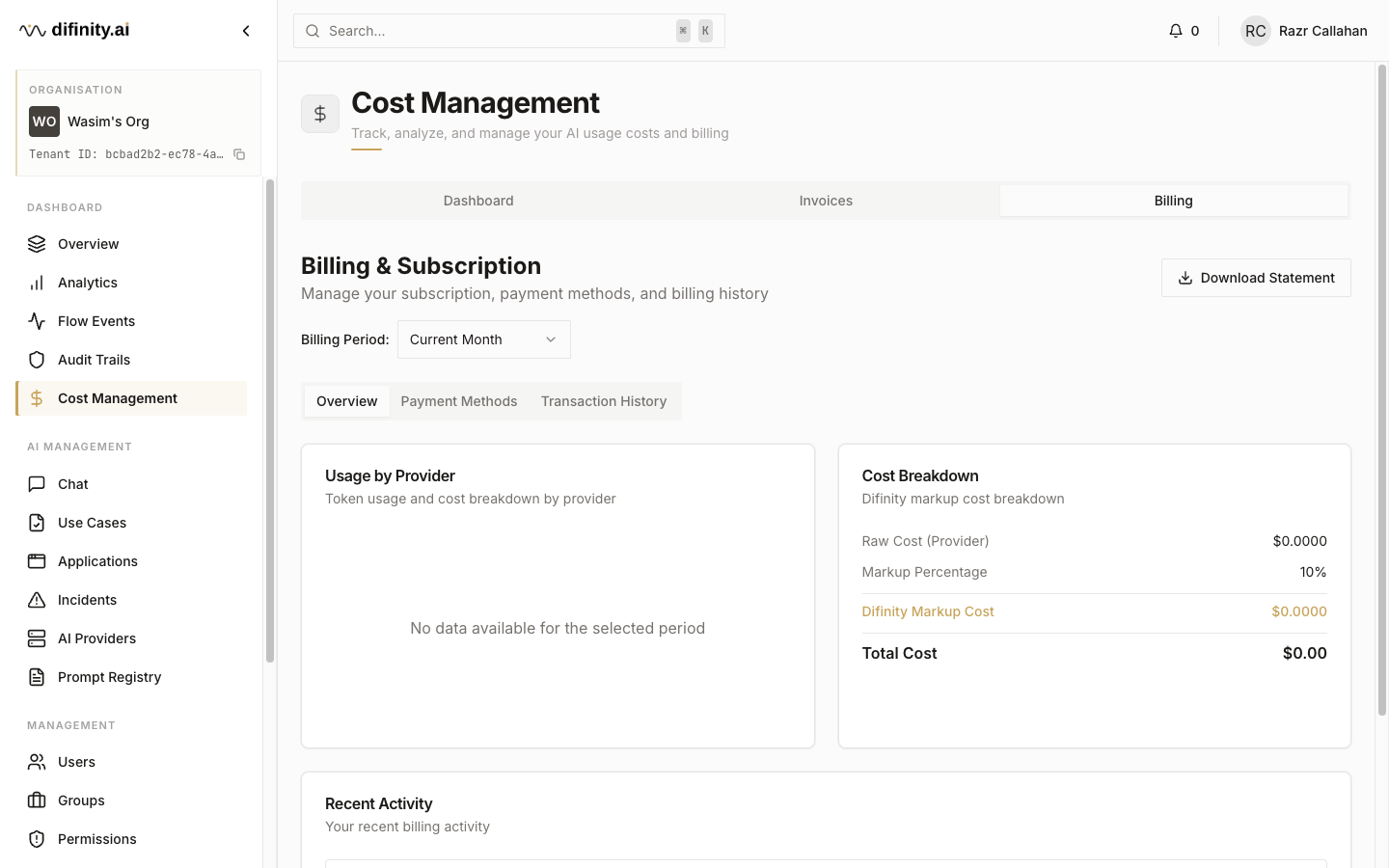
Cost Management provides full financial visibility across AI spending, with three tabs:
- Dashboard — cost analytics over time, savings analysis (comparing actual cost against unoptimised routing), and cost breakdown by model.
- Invoices — billing statements with downloadable records.
- Billing — usage by provider, cost breakdown including markup, payment methods, and transaction history.
Date range filters apply across all tabs. Costs are tracked in real time as requests flow through the platform.
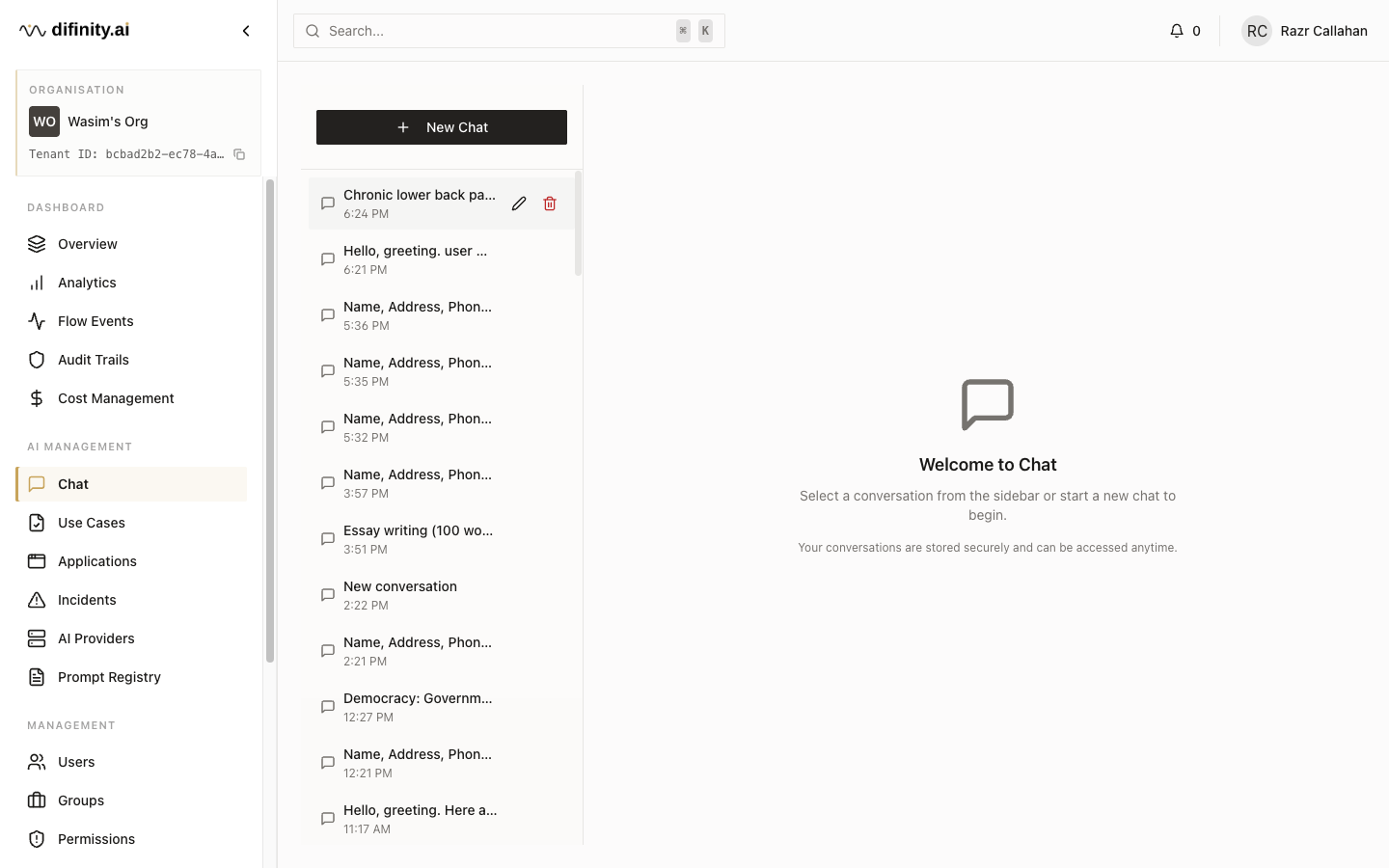
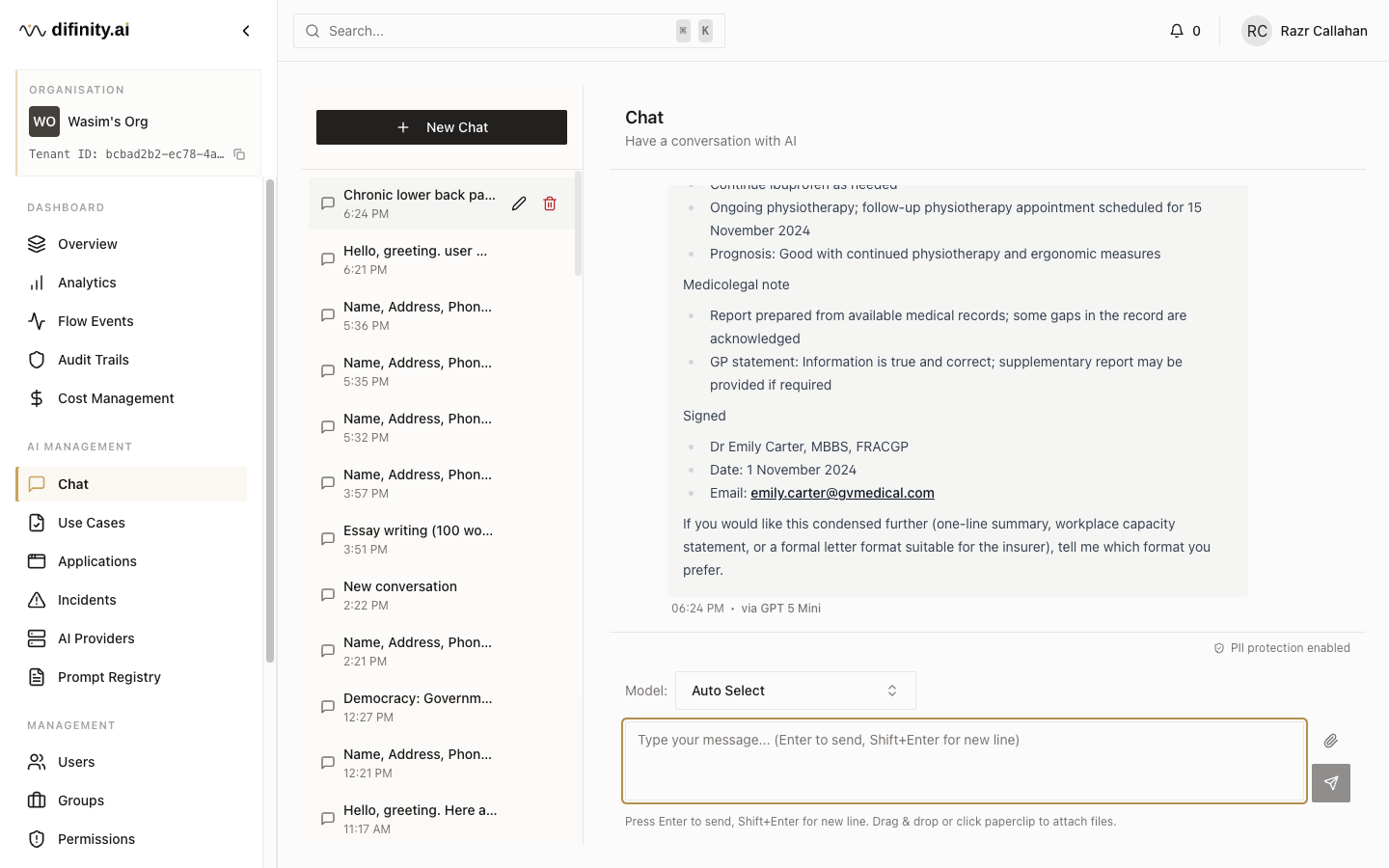
Chat
Hub includes a built-in conversational AI interface governed by the same compliance rules applied to API workloads. It is useful for administrators testing use case configurations and for teams who need governed AI chat without a separate application deployment.
The interface provides a conversation sidebar with history, model selection (auto-routing or a specific model), real-time streaming, a PII protection status indicator, file attachment support, and automatic conversation title generation.
Use Cases
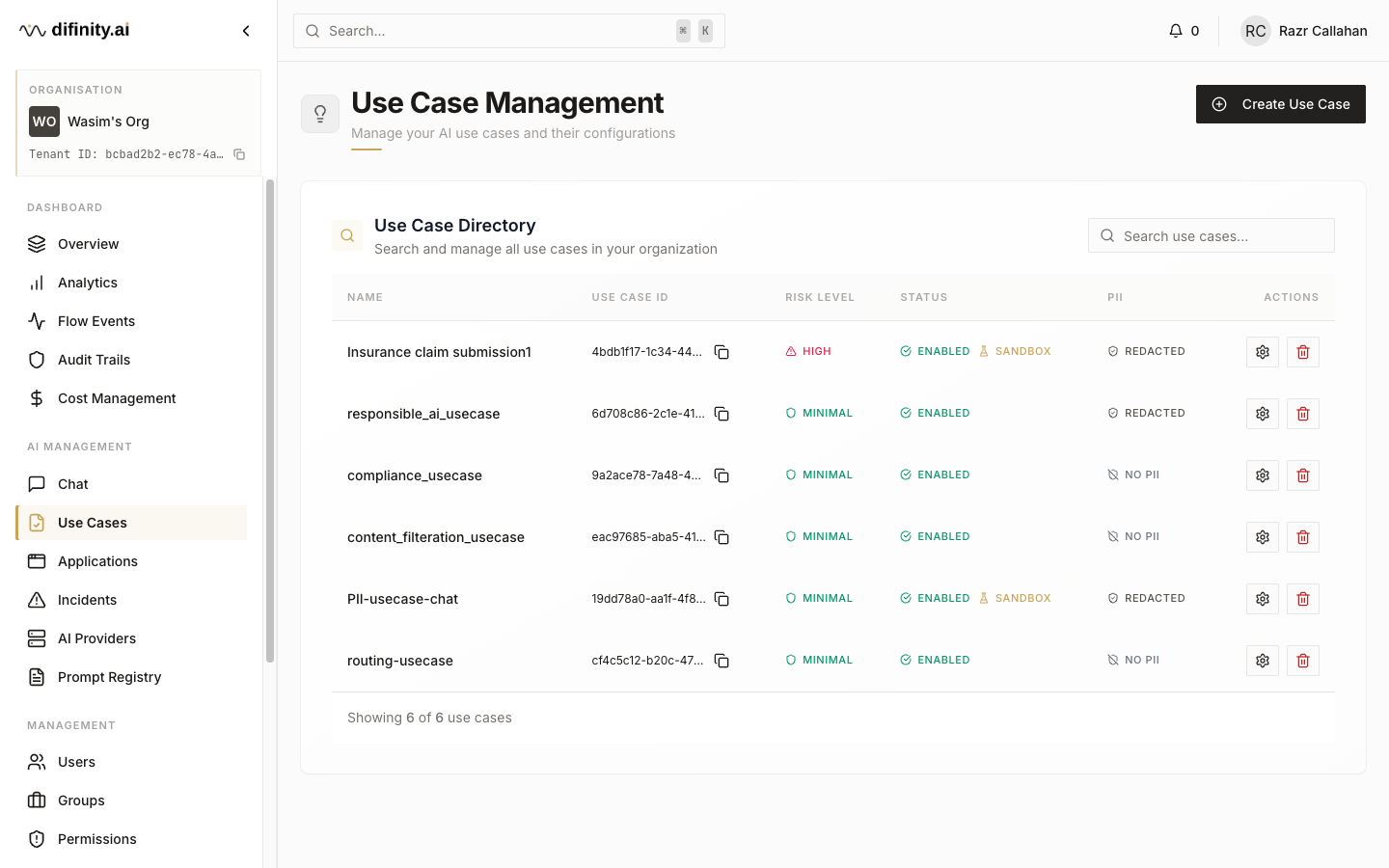
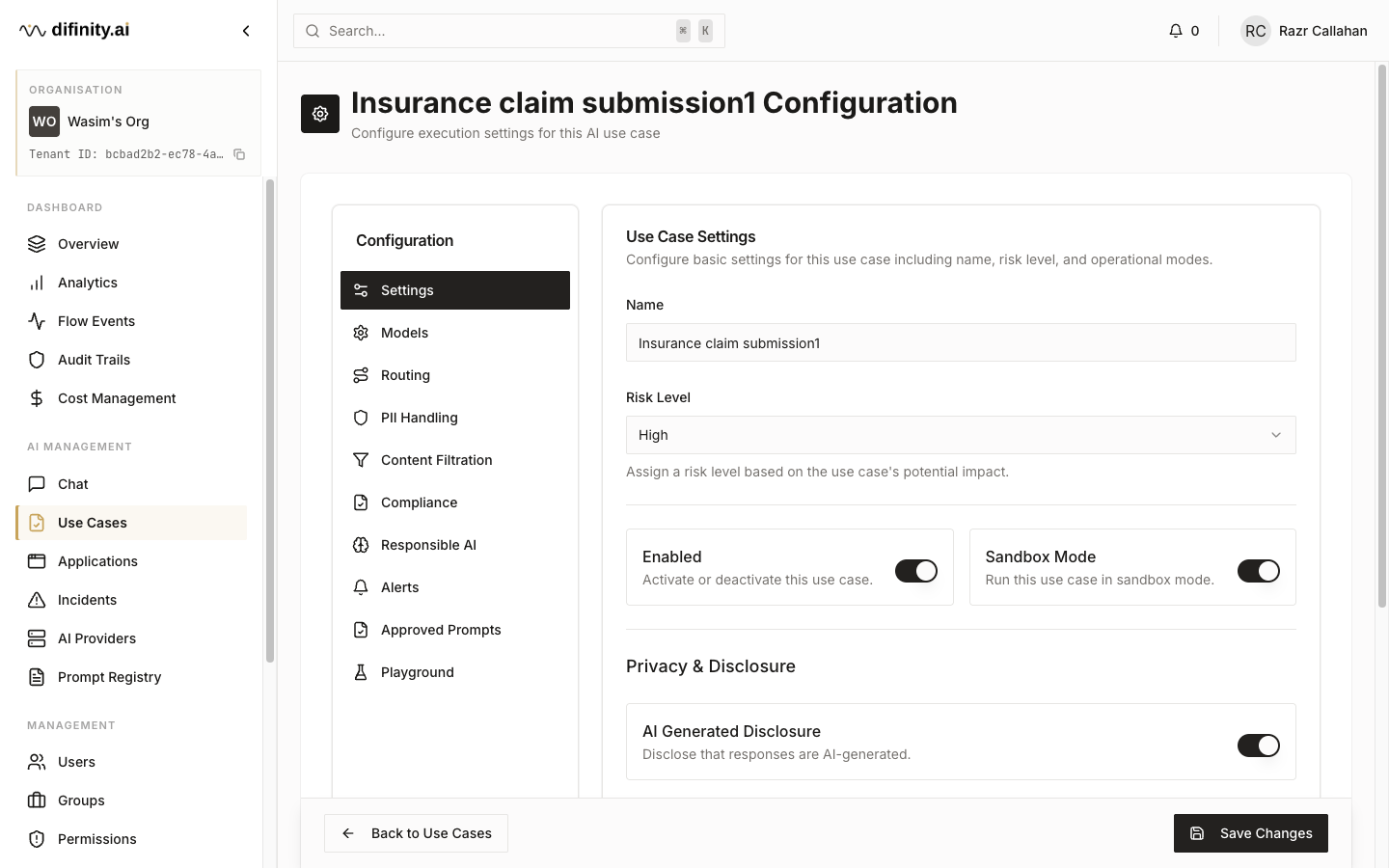
Use Cases are the central configuration unit of the platform. Each use case defines how a category of AI workload should be processed — what models are available, what compliance checks apply, how PII is handled, and what routing strategy to use.
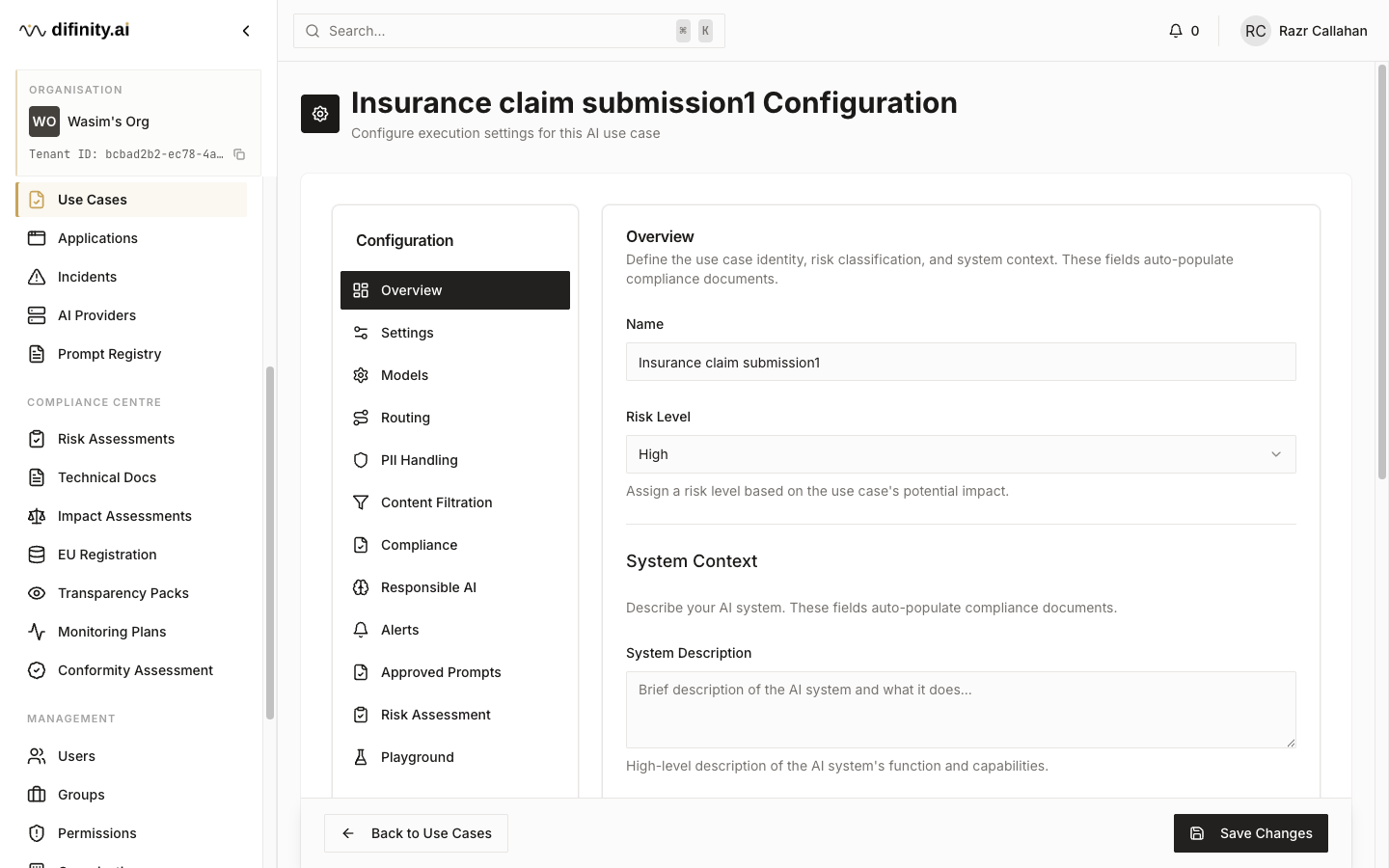
The use case directory shows each use case's name, ID, risk level (MINIMAL / LIMITED / HIGH), status (Enabled / Disabled / Sandbox), and PII handling mode. Creating or editing a use case opens a twelve-tab configuration panel:
| Tab | Purpose |
|---|---|
| Overview | Name, risk level classification, system context prompt |
| Settings | Toggles for enabled state, sandbox mode, AI disclosure notice, human escalation trigger |
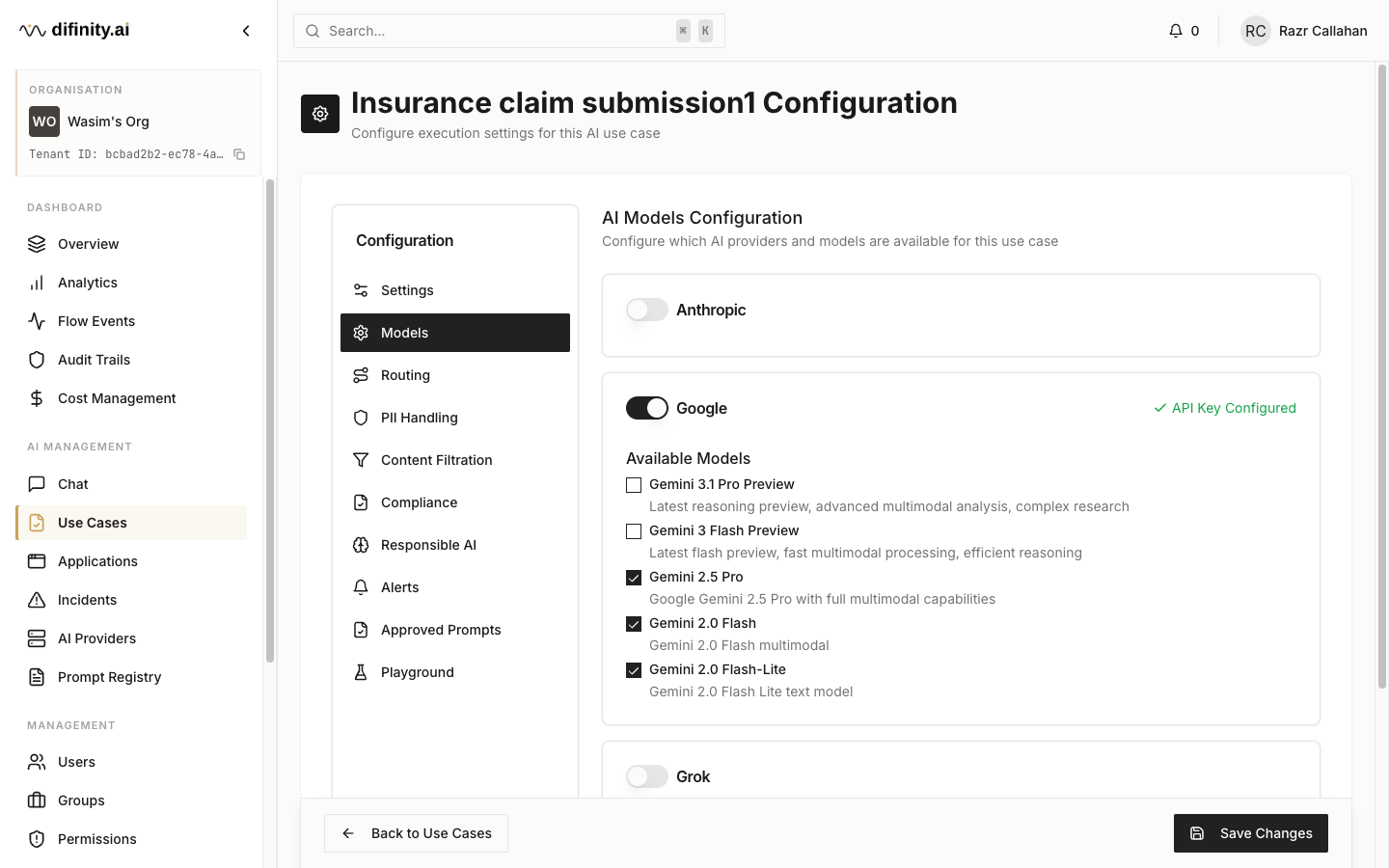
| Models | Enable or disable specific models per provider |
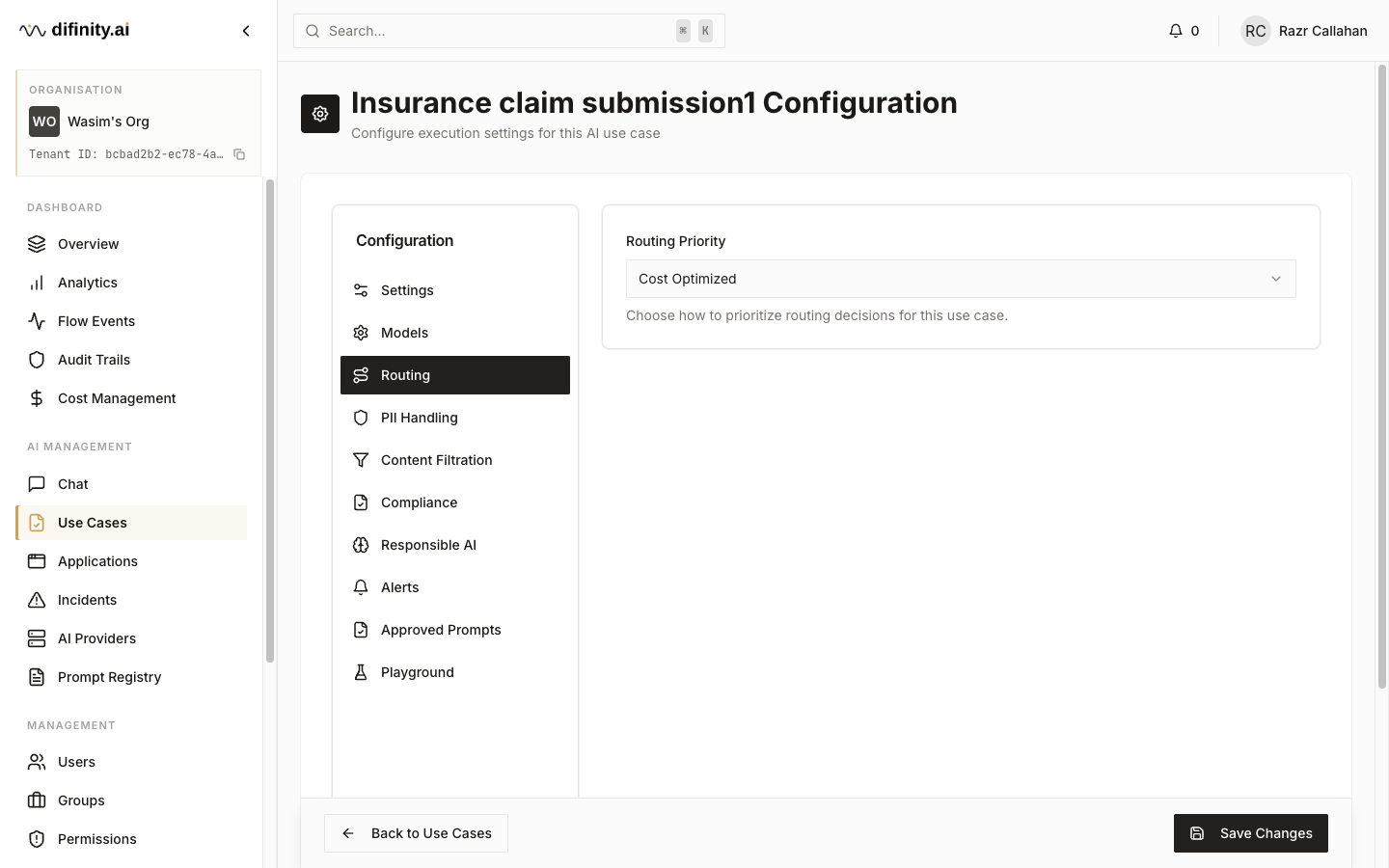
| Routing | Strategy selection: Cost, Performance, or Accuracy |
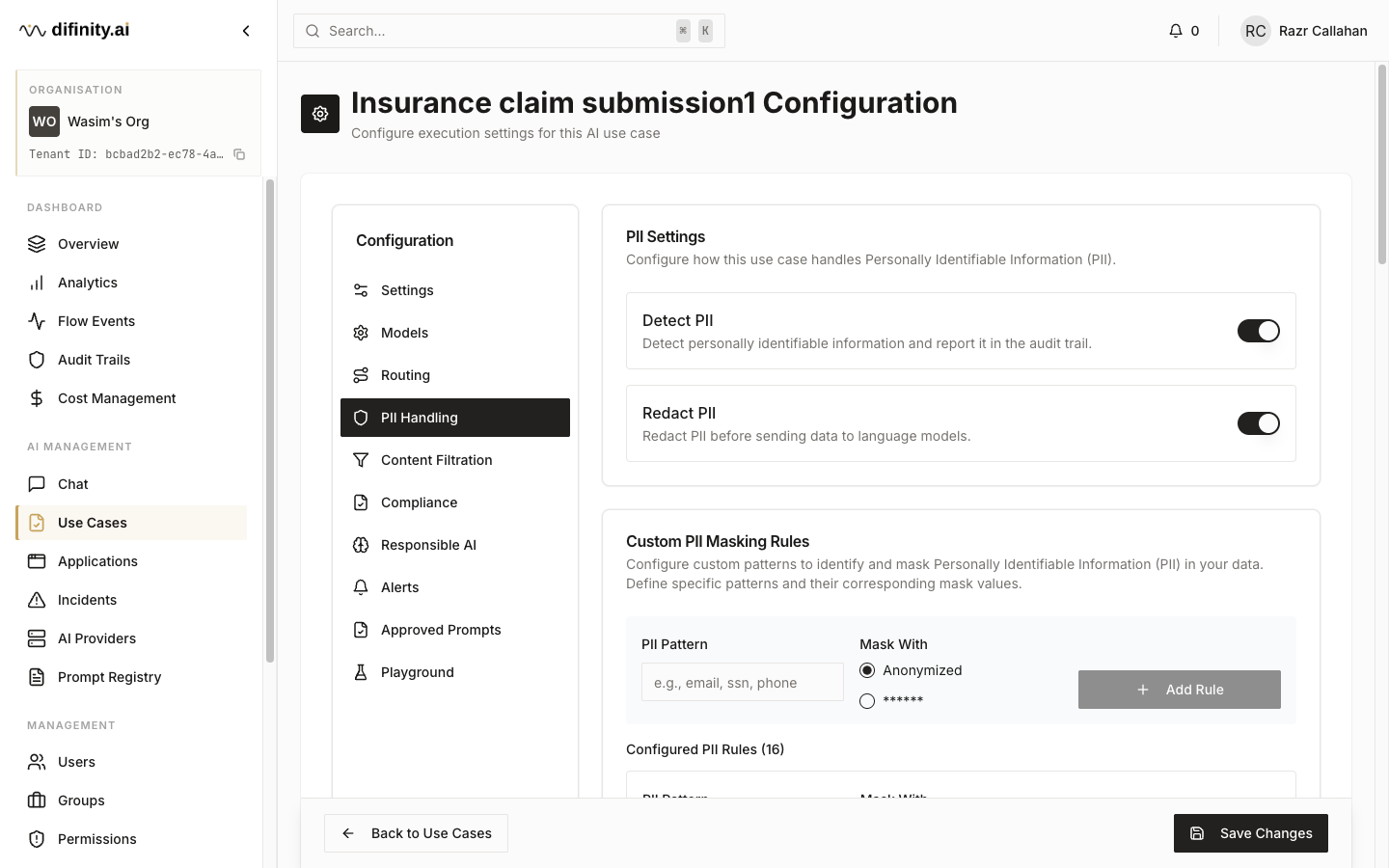
| PII Handling | Detection sensitivity, redaction mode, entity types |
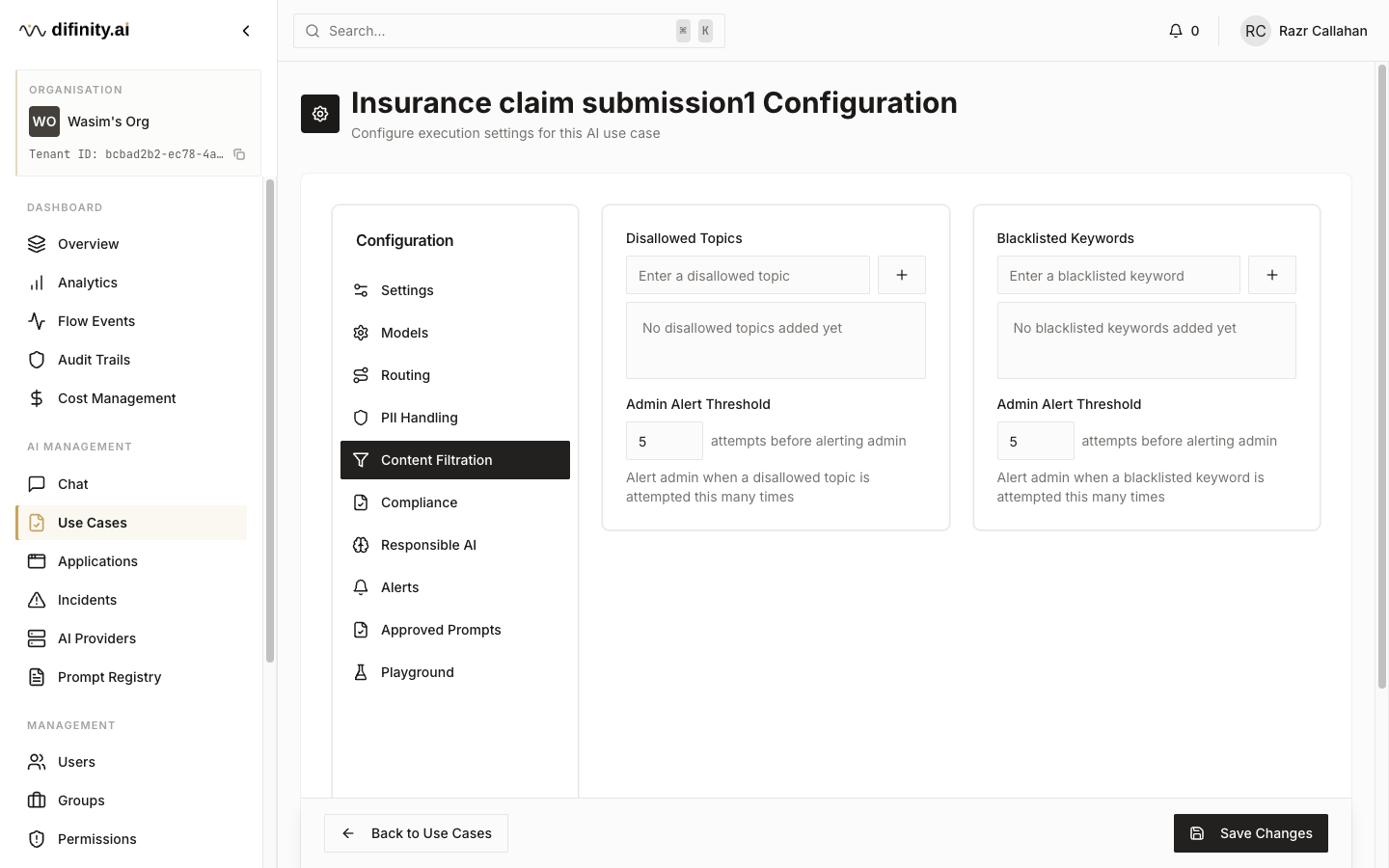
| Content Filtration | Blacklisted keywords and disallowed topic definitions |
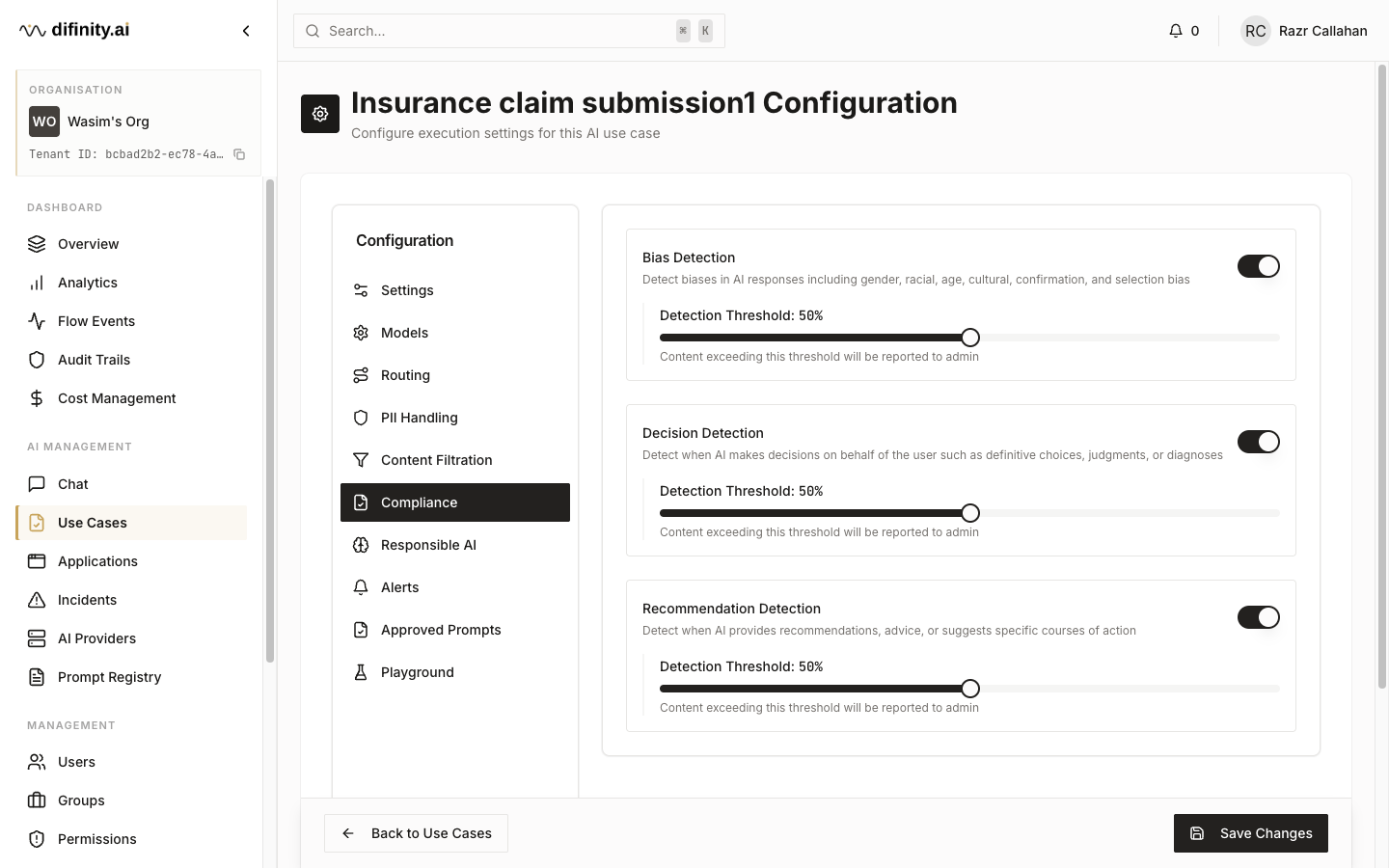
| Compliance | Bias detection, decision support, and recommendation detection settings |
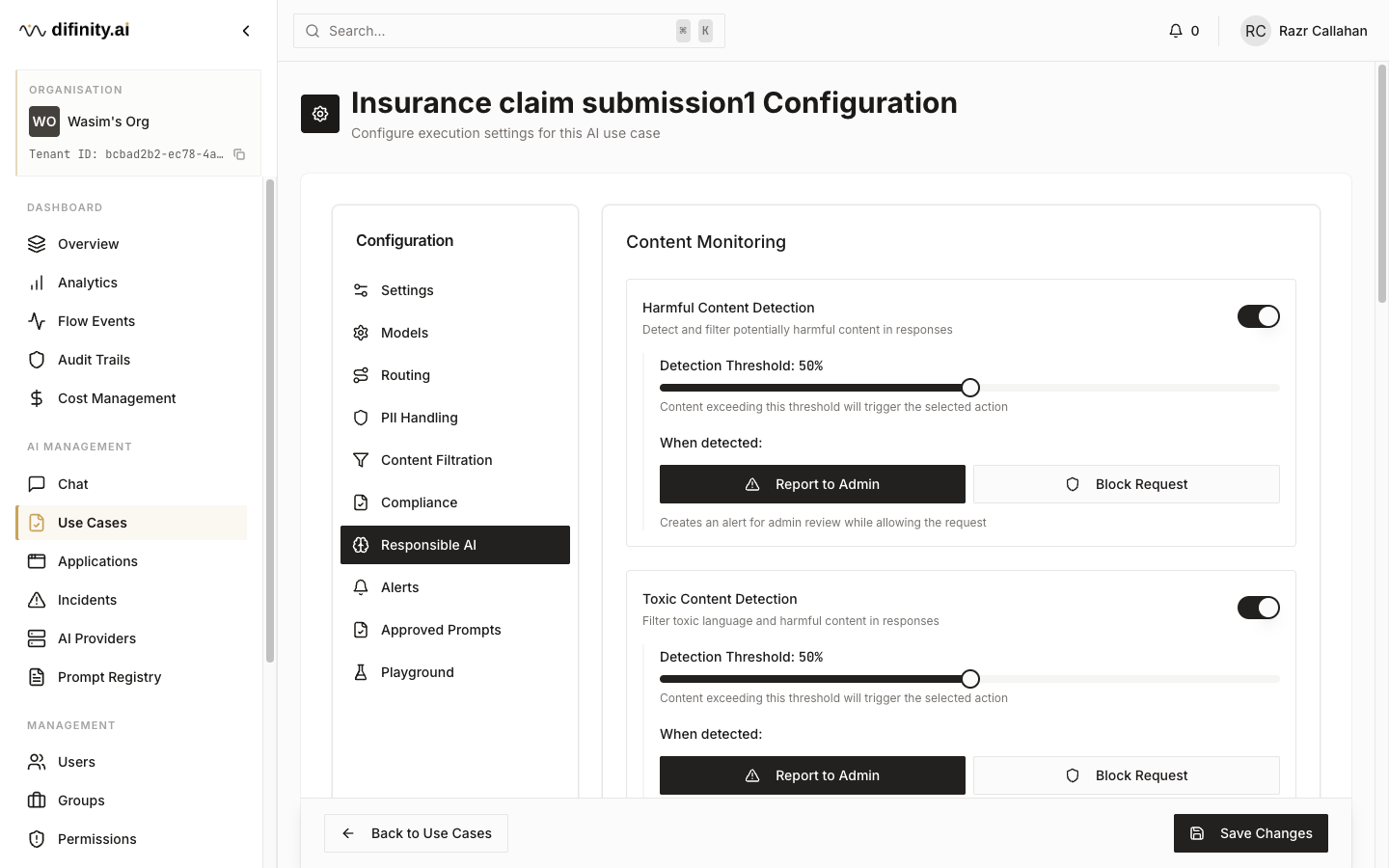
| Responsible AI | Harmful content, toxicity, phishing, manipulative behaviour, insensitive language, social scoring, and fake news thresholds |
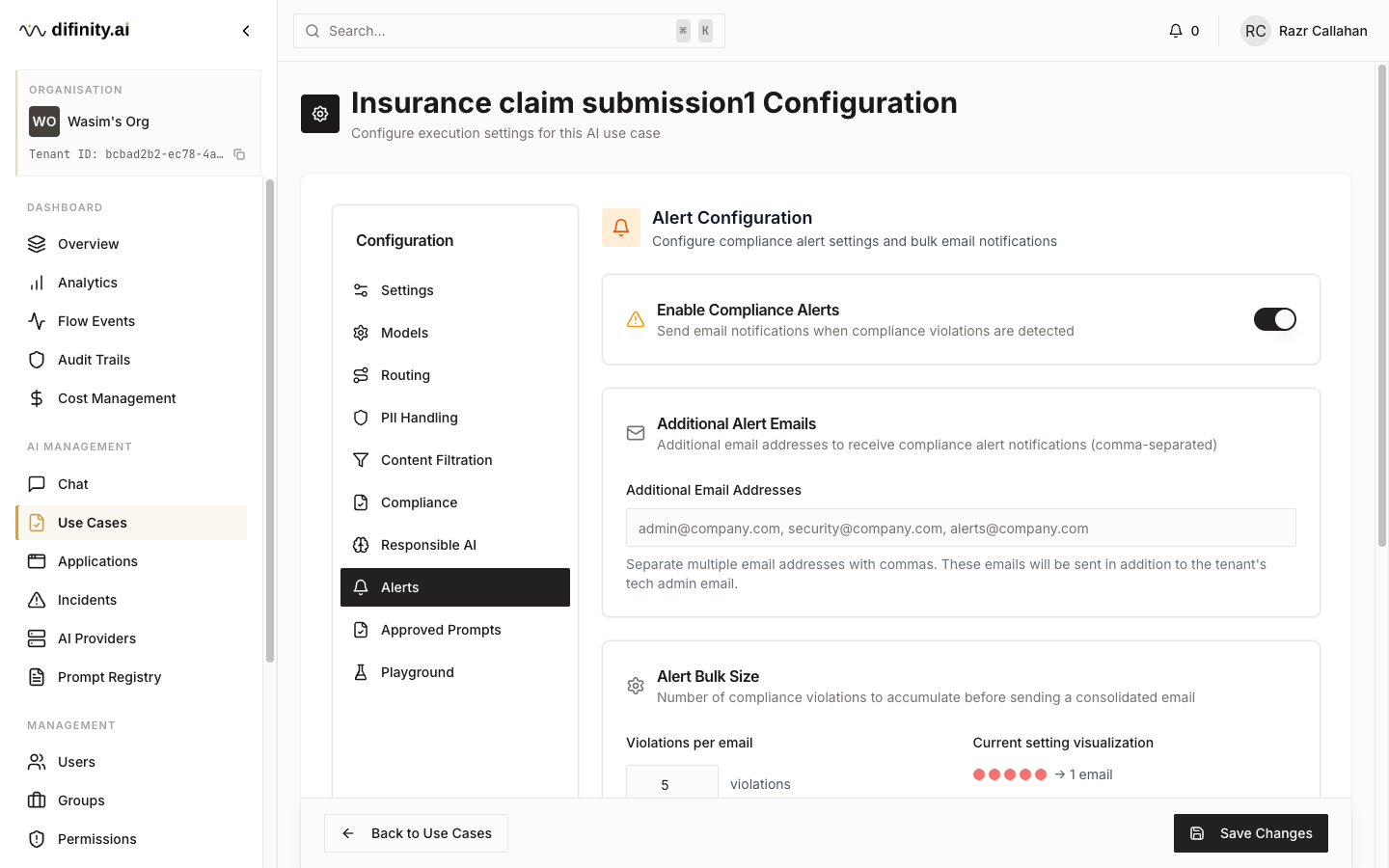
| Alerts | Threshold-based alerting and notification configuration |
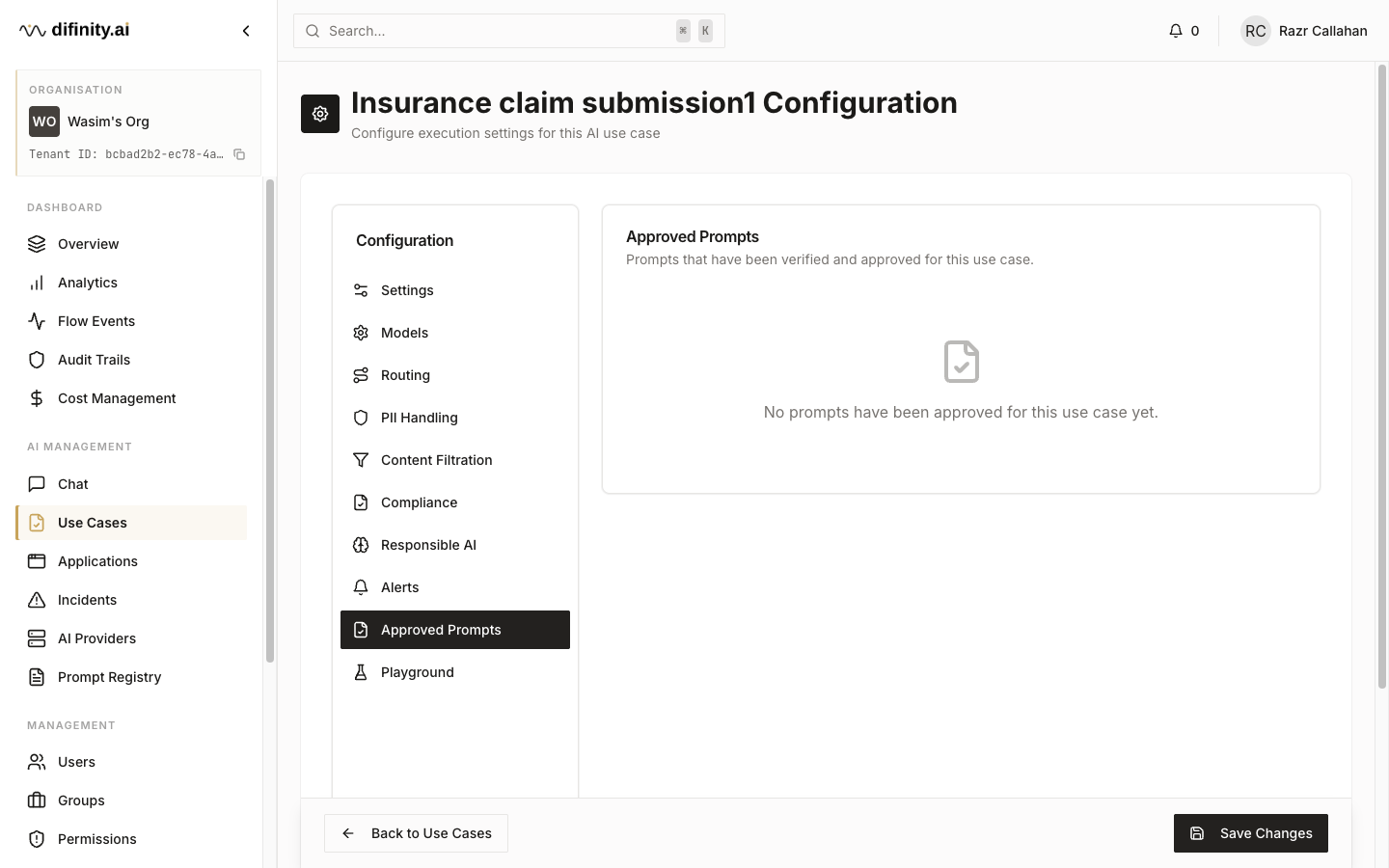
| Approved Prompts | Link to verified prompts from the Prompt Registry |
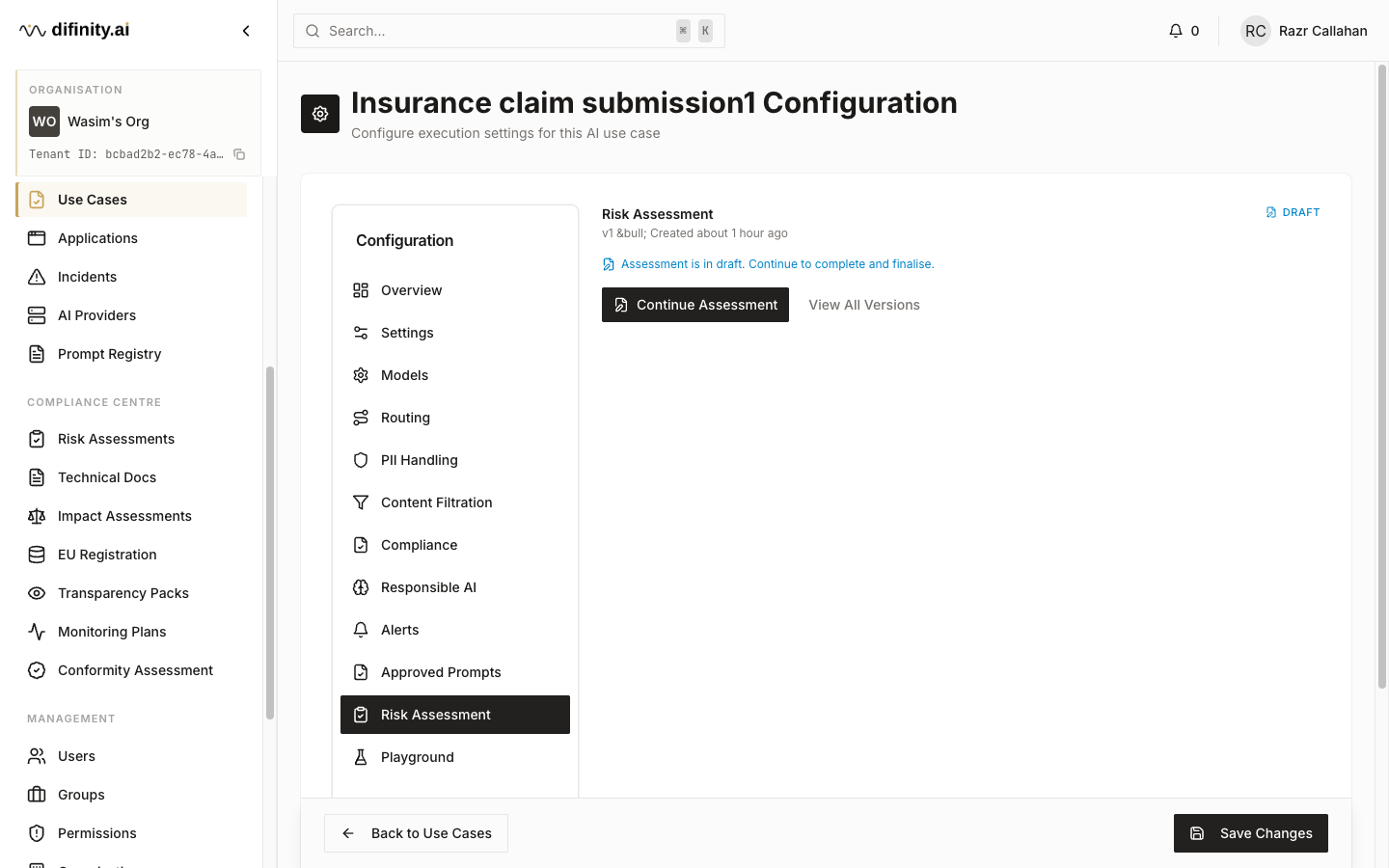
| Risk Assessment | Associated EU AI Act risk assessment |
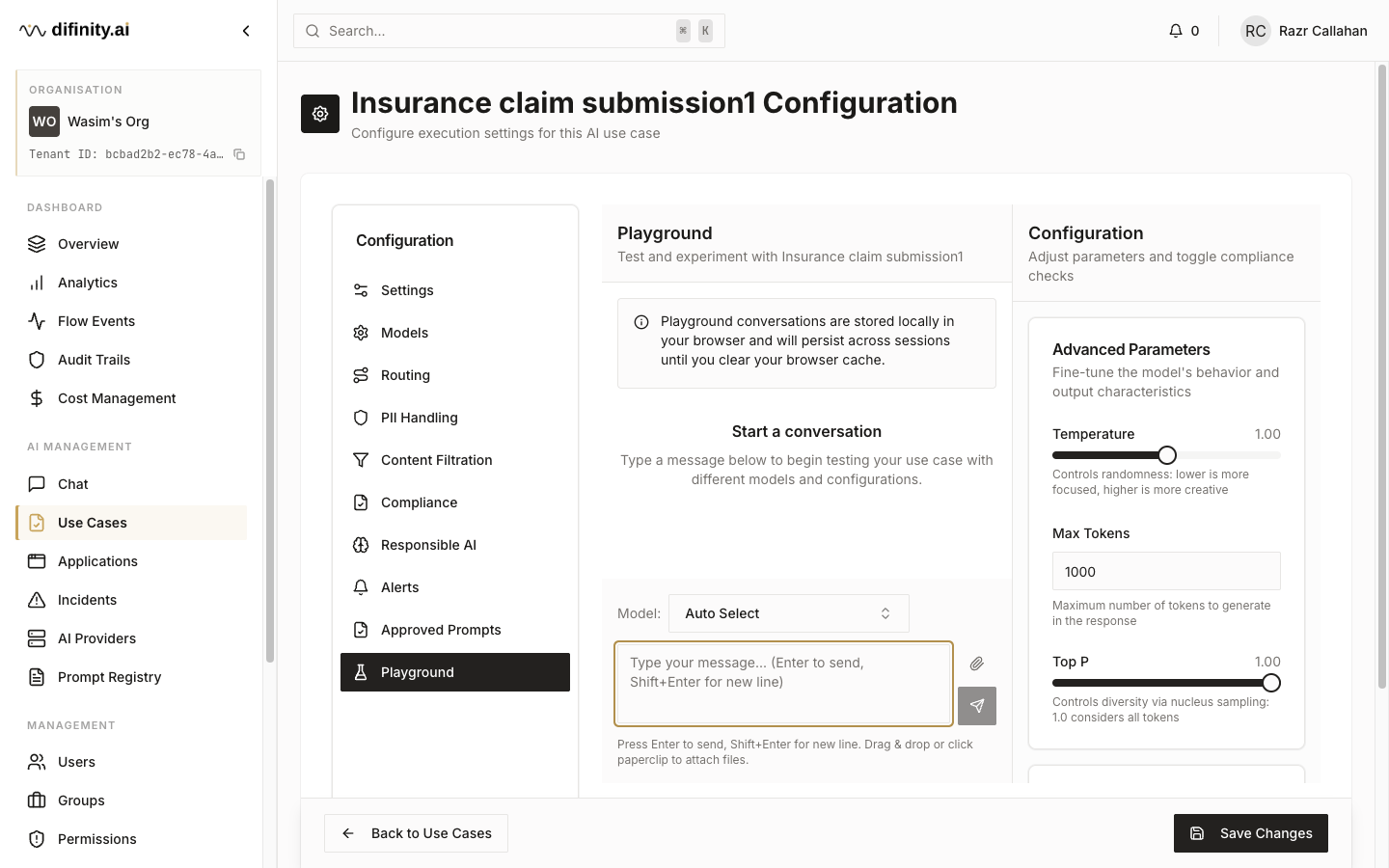
| Playground | Live test environment for the current configuration |
Applications
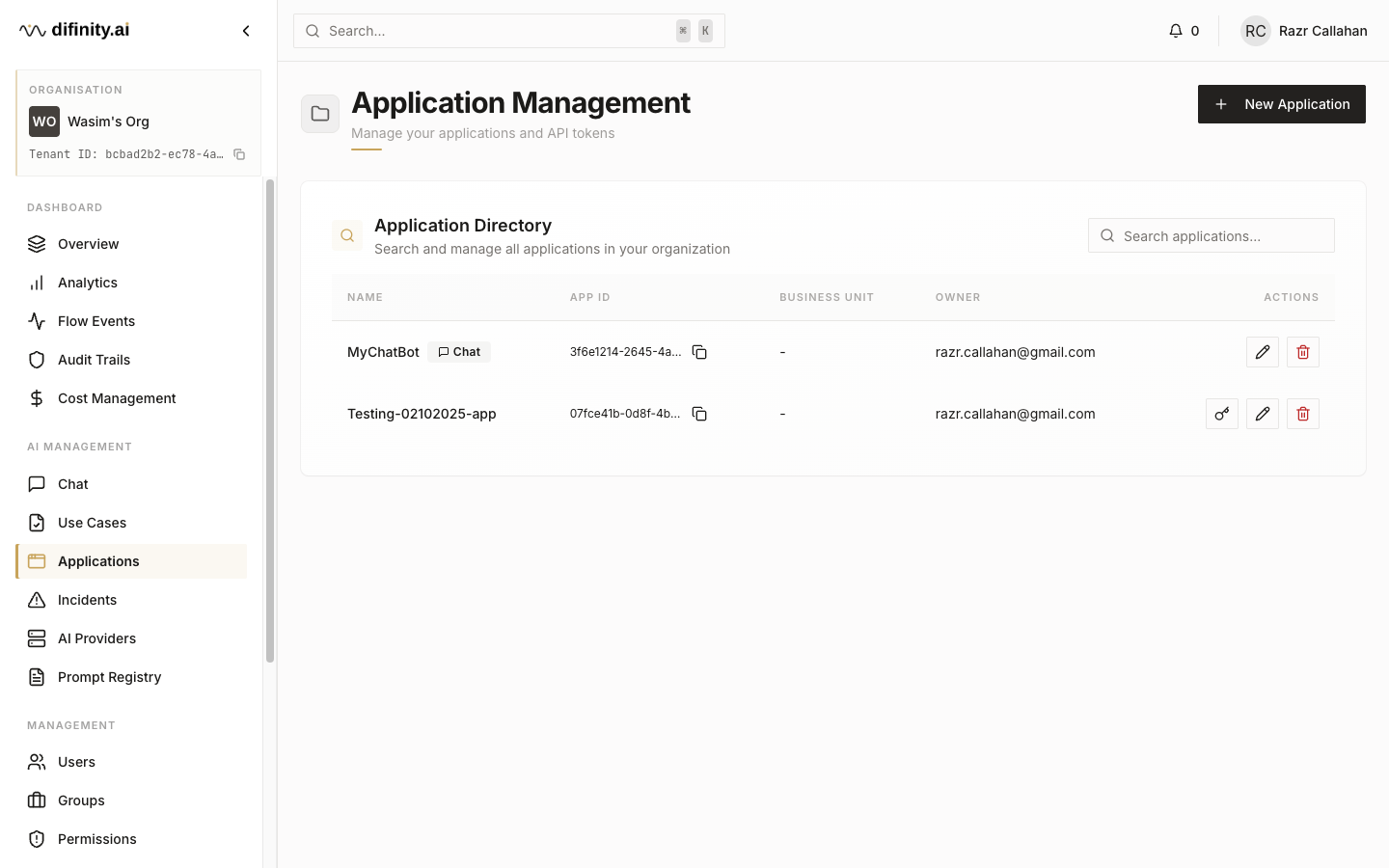
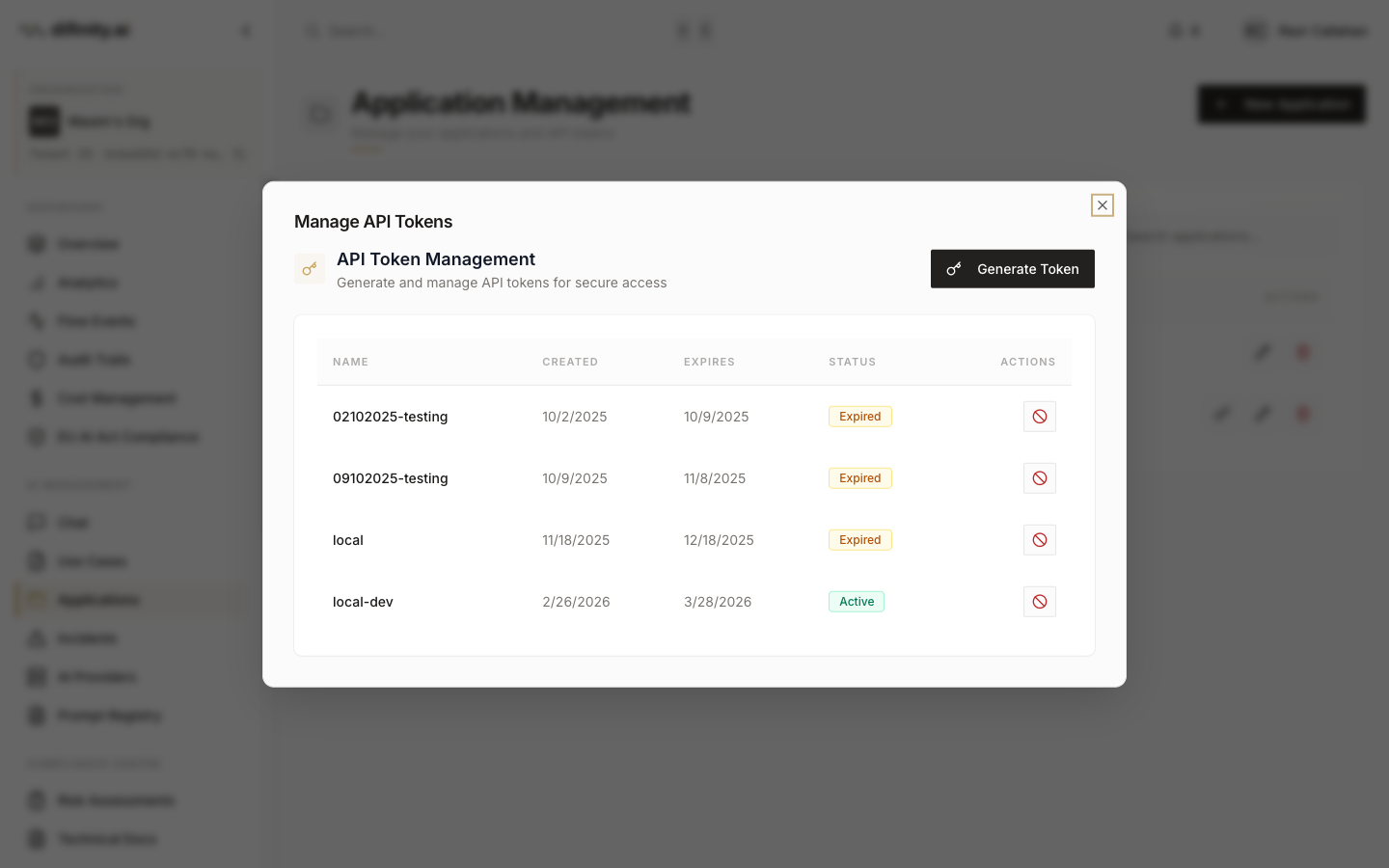
Applications represent the systems or services that consume the Flow API. Registering an application generates API tokens scoped to specific use cases, enabling per-application usage tracking, cost attribution, and access control.
Two application types are supported:
- API — supports multiple tokens, for backend services and integrations.
- Chat — one token per tenant, for the Hub chat interface.
Application fields include name, owner email, purpose description, business unit, cost unit, a custom application ID, and assigned use cases.
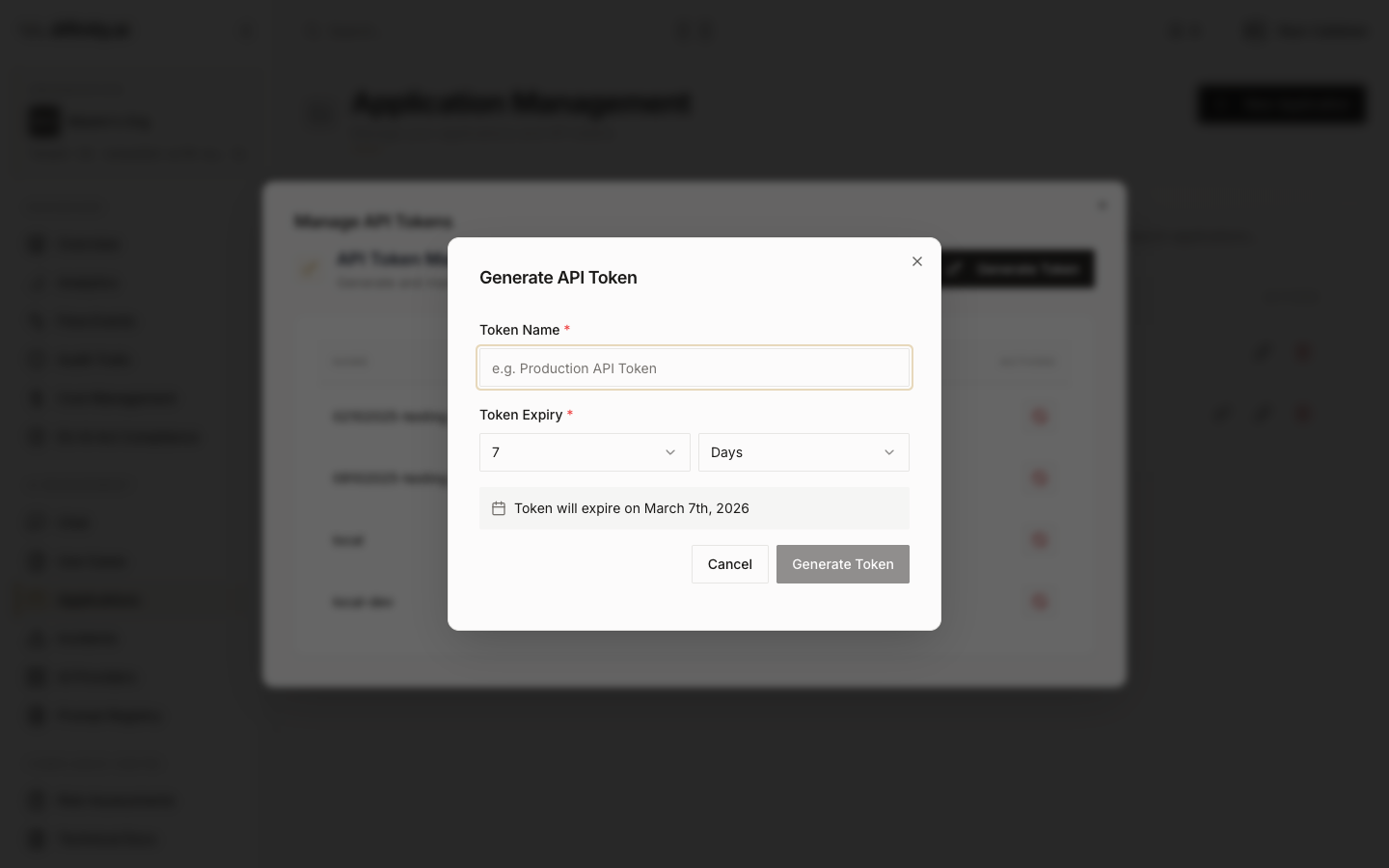
Token management allows generating new tokens (the token value is shown once at generation time), copying, and revoking. Tokens are scoped to the application's assigned use cases — requests using a token can only call use cases that application is permitted to access.
Incidents
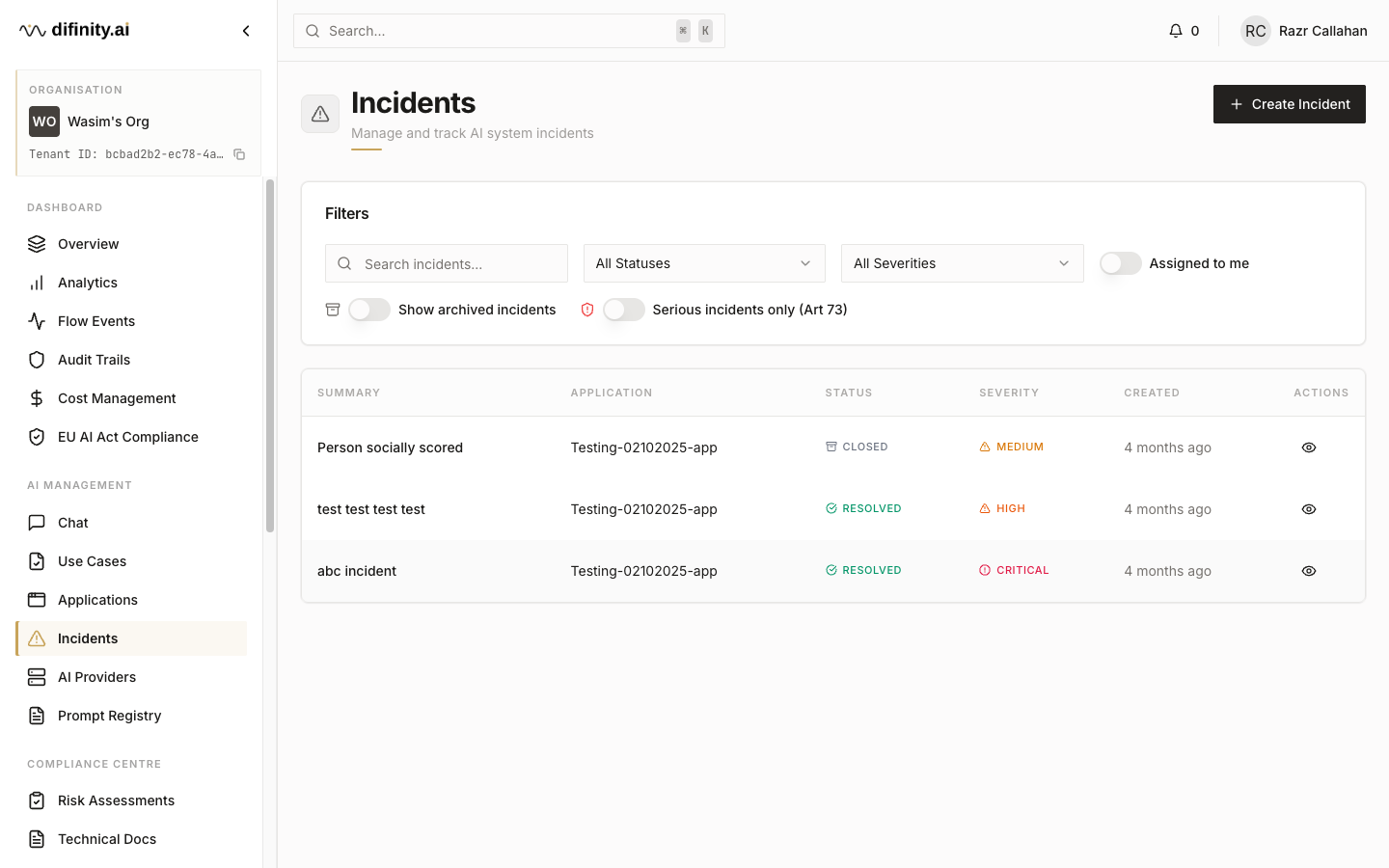
The Incidents module tracks AI system incidents including compliance violations, model failures, and anomalous behaviour. It supports a structured lifecycle workflow:
Status progression: Reported → Acknowledged → Investigating → Escalated (L1 / L2 / L3) → Mitigated → Resolved → Reopened → Closed
Severity levels: Low, Medium, High, Critical, Emergency
Each incident has a detail page with a timeline of status changes, internal notes, and an Audit / Post-Mortem tab for structured retrospective documentation.
AI Providers
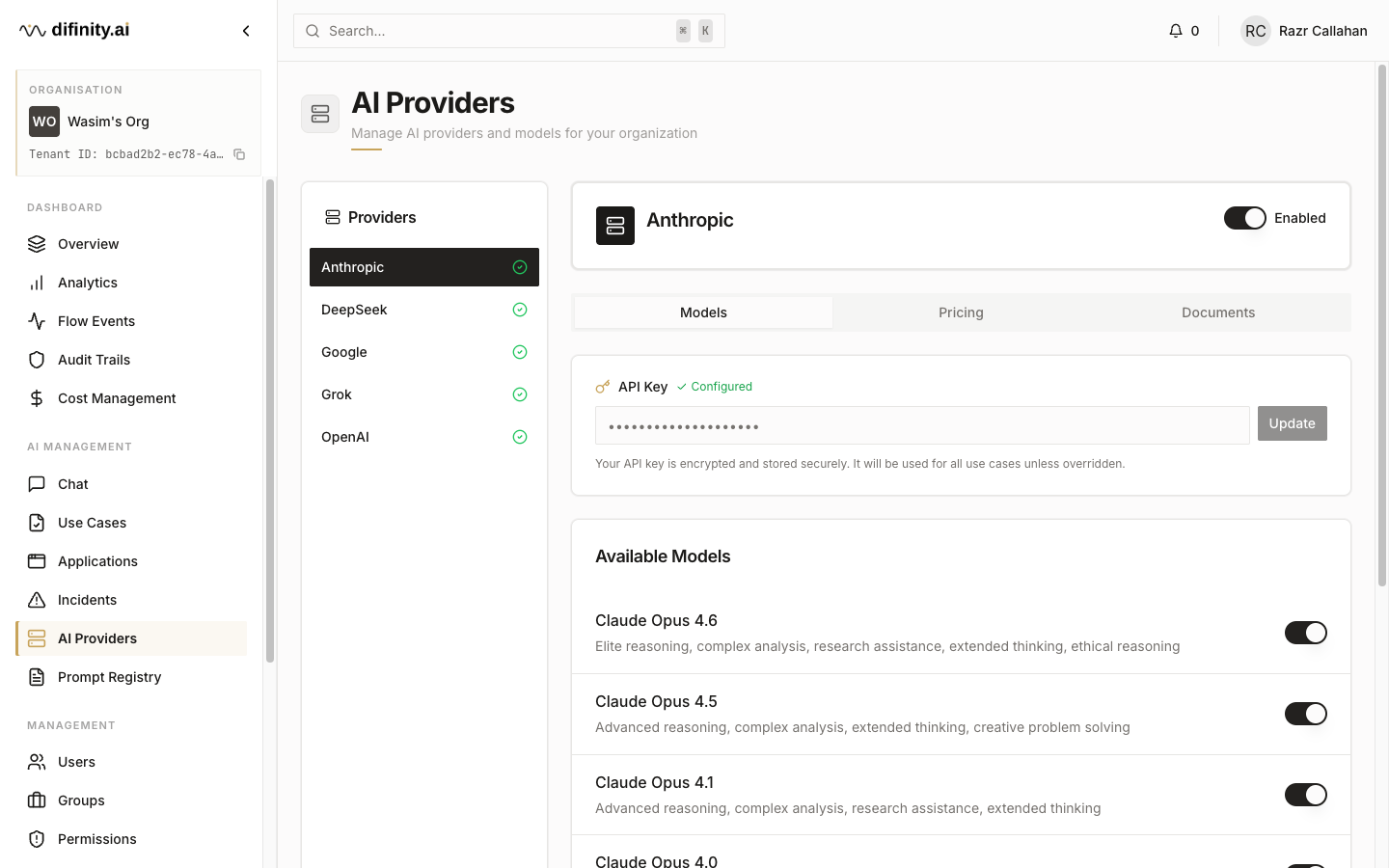
AI Providers is where provider-level configuration is managed. Difinity supports OpenAI, Anthropic, Google, DeepSeek, and Grok. Providers can be enabled or disabled globally, and individual models within each provider can be toggled independently.
Each provider has three configuration tabs:
- Models — API key entry and model-level enable/disable toggles.
- Pricing — input and output token costs, used for cost tracking and markup calculations.
- Documents — provider-specific documentation and notes.
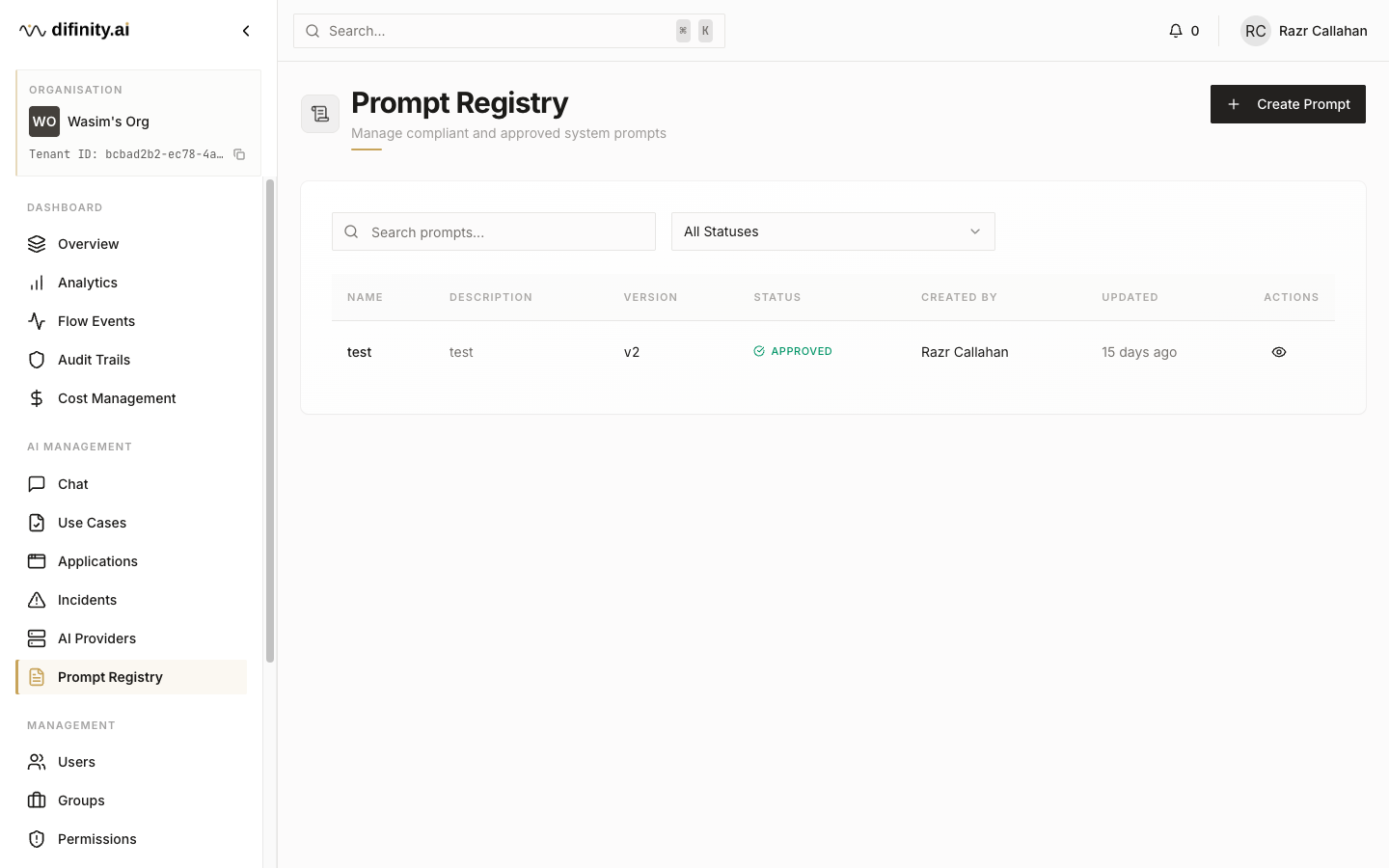
Prompt Registry
The Prompt Registry is the governance system for system prompts. It provides versioning, peer review, and an approval workflow to ensure that prompts used in production AI workloads have been reviewed and authorised.
Approval workflow: Draft → Verified → Pending Approval → Approved / Rejected
Prompts are reviewed in the context of specific use cases. Reviewers can leave comments and view version history before approving or rejecting. Approved prompts are linked to use cases via the Approved Prompts tab in use case configuration.
Compliance Centre
The Compliance Centre consolidates the tools required for formal regulatory compliance under EU AI Act and ISO 42001.
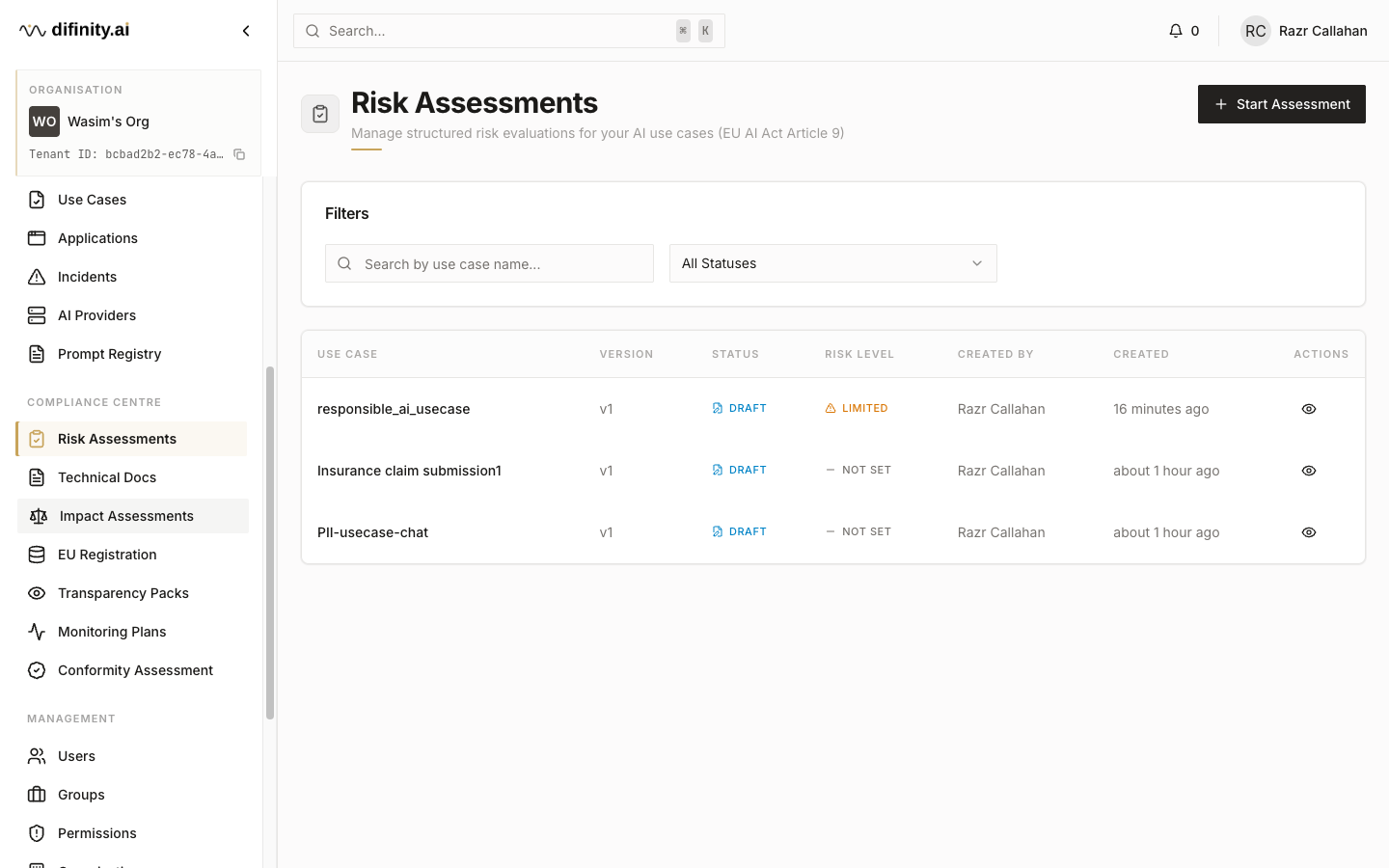
Risk Assessments
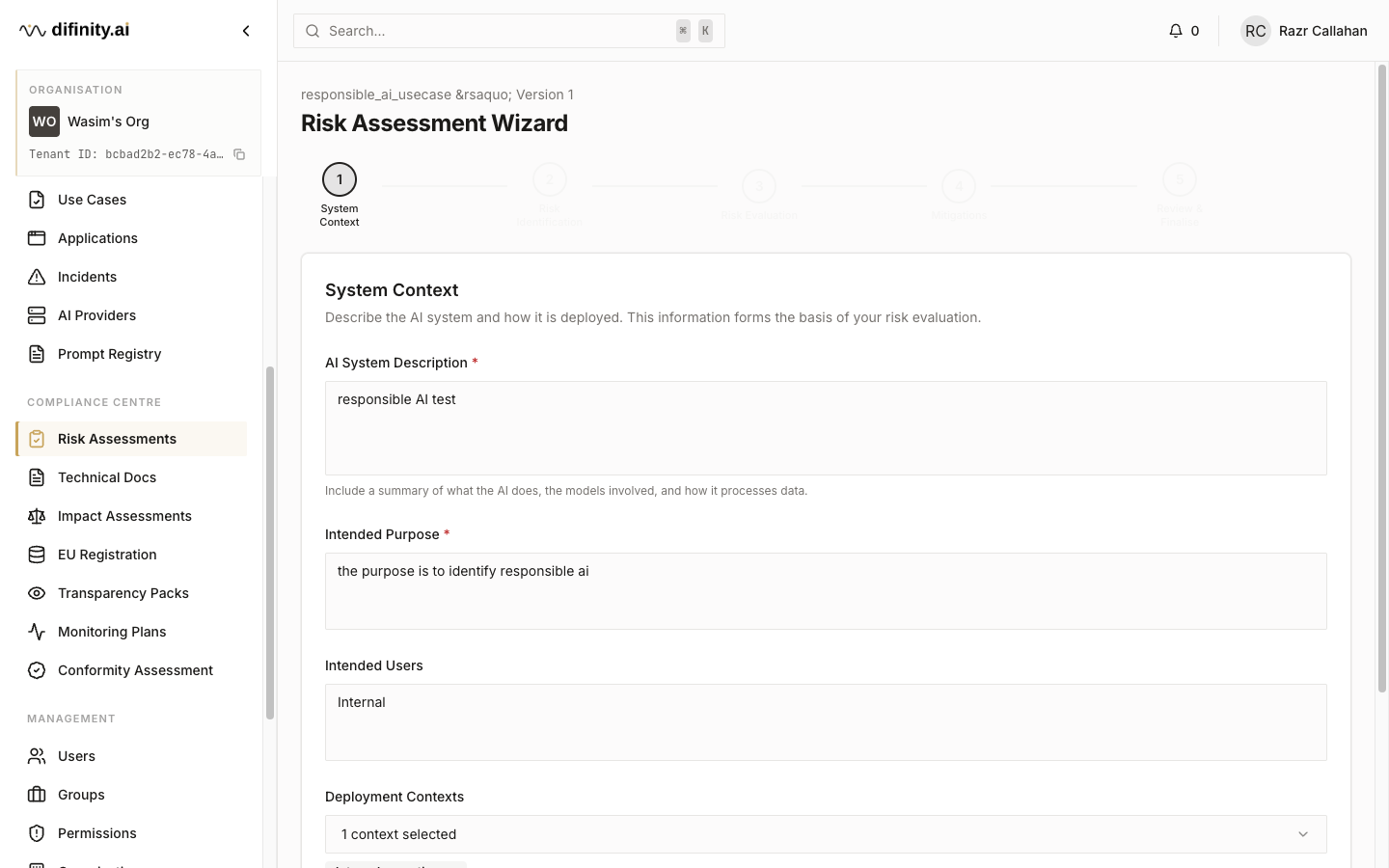
Risk Assessments satisfy the EU AI Act Article 9 requirement for a risk management system. Each assessment is created through a five-step wizard:
- System Context — define the AI system being assessed, its purpose, and deployment context.
- Risk Identification — select applicable risks from the platform's risk catalogue.
- Risk Evaluation — assess likelihood and impact for each identified risk.
- Mitigations — document controls and mitigations applied to each risk.
- Review — final review and sign-off.
Assessment statuses: Draft, Active, Complete, Superseded.
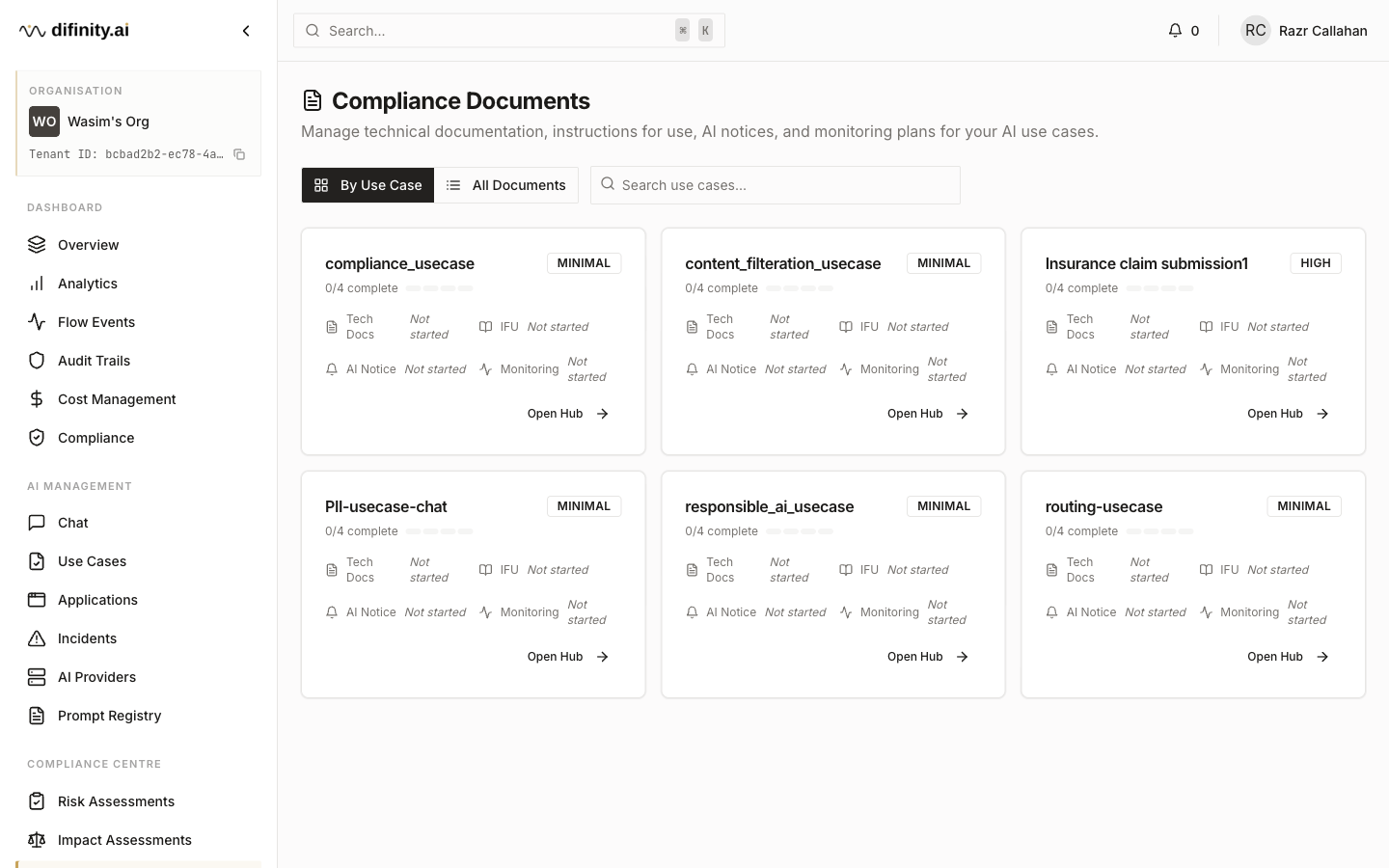
Compliance Documents
Compliance Documents is a unified hub for all formal documentation required under EU AI Act. Four document types are supported:
| Document Type | Regulatory Reference |
|---|---|
| Technical Documentation | Art. 11, Annex IV |
| Instructions for Use | Art. 13 |
| AI Disclosure Notices | Art. 50 |
| Monitoring Plans | Art. 72 |
Documents can be viewed by use case (card grid) or across all use cases (flat table). AI-assisted drafting is available via the Flow API compliance generation endpoints.
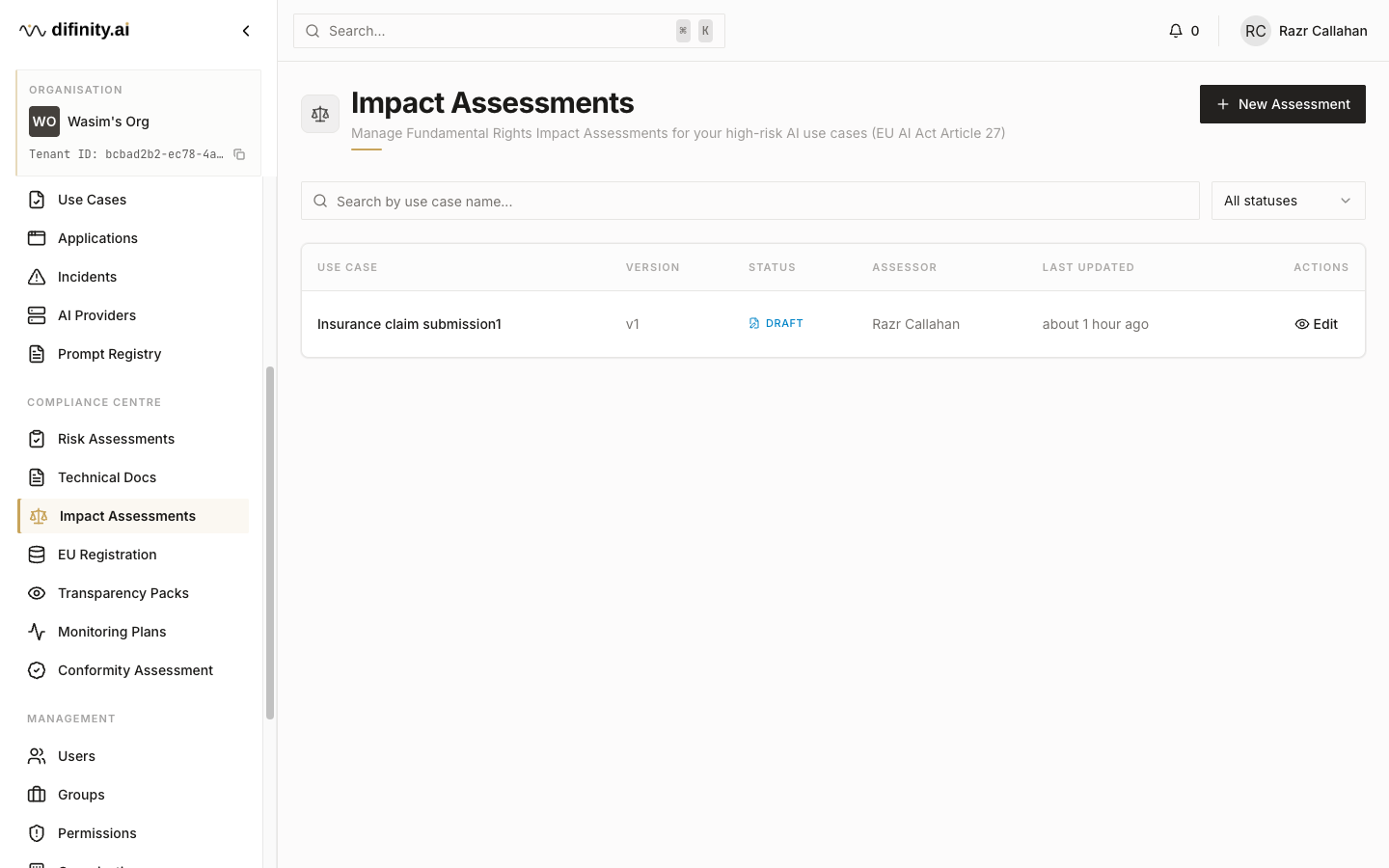
Impact Assessments (FRIA)
Fundamental Rights Impact Assessments satisfy EU AI Act Article 27 requirements for HIGH-risk AI systems. Each assessment evaluates the system's potential impact across four dimensions: non-discrimination, privacy, data protection, and human dignity. FRIAs are associated with specific use cases classified as HIGH risk.
Conformity and Registration
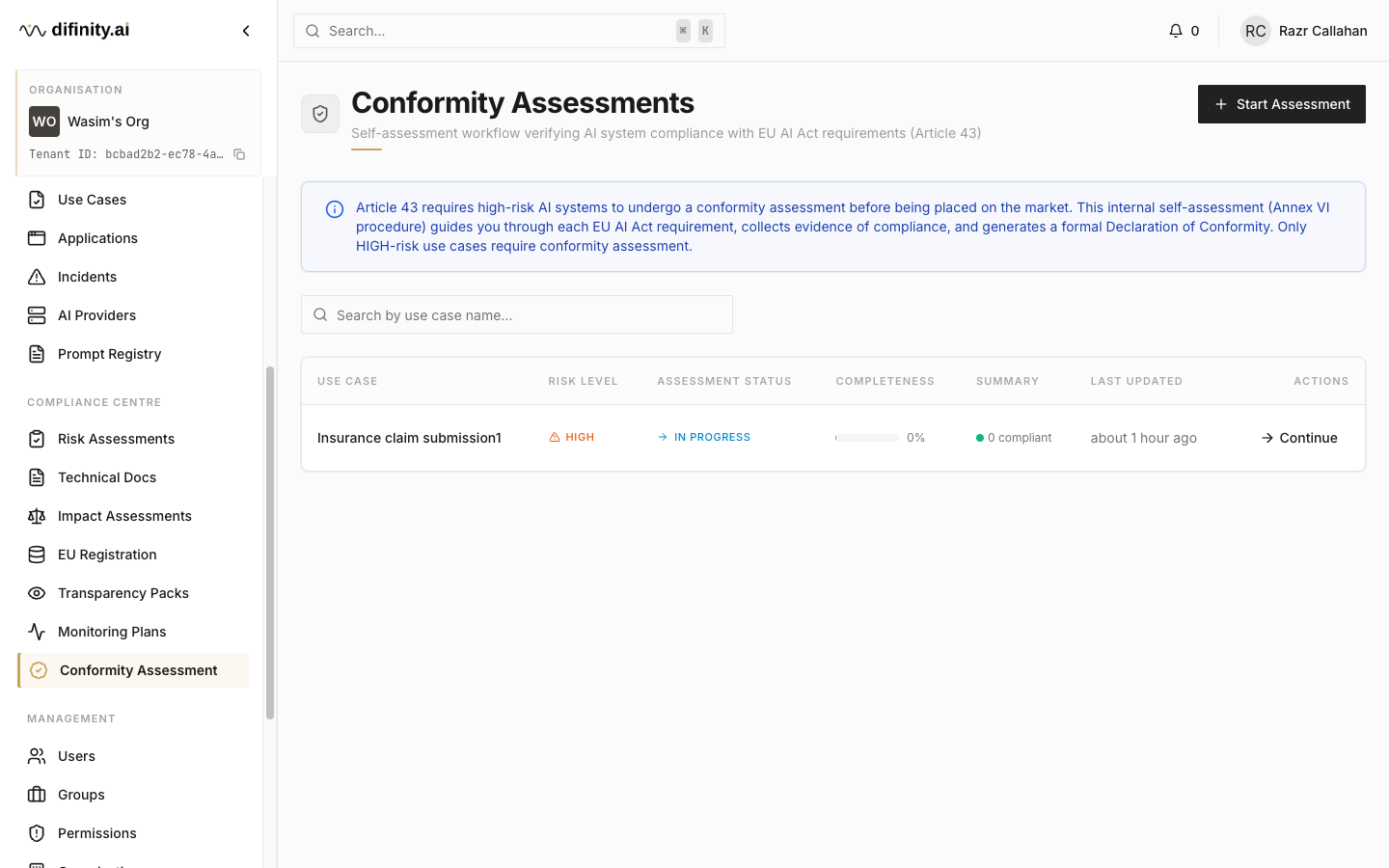
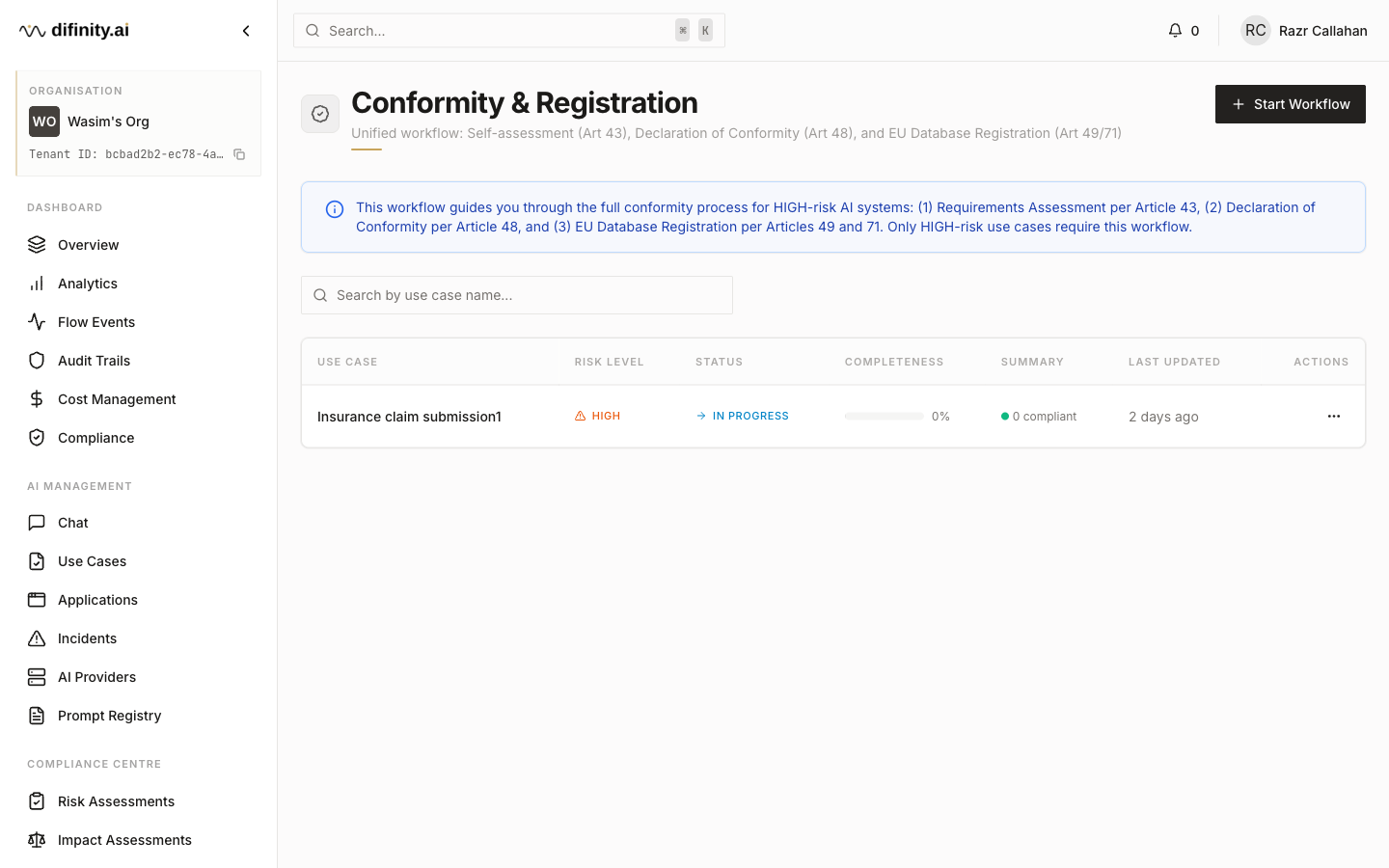
The Conformity and Registration module guides HIGH-risk AI systems through the three-step compliance workflow required before deployment:
- Self-Assessment — structured conformity assessment per Art. 43 and Annex VI.
- Declaration of Conformity — generate and manage the Art. 48 declaration.
- EU Database Registration — record the system in the EU AI database per Art. 49/71.
AIMS Governance
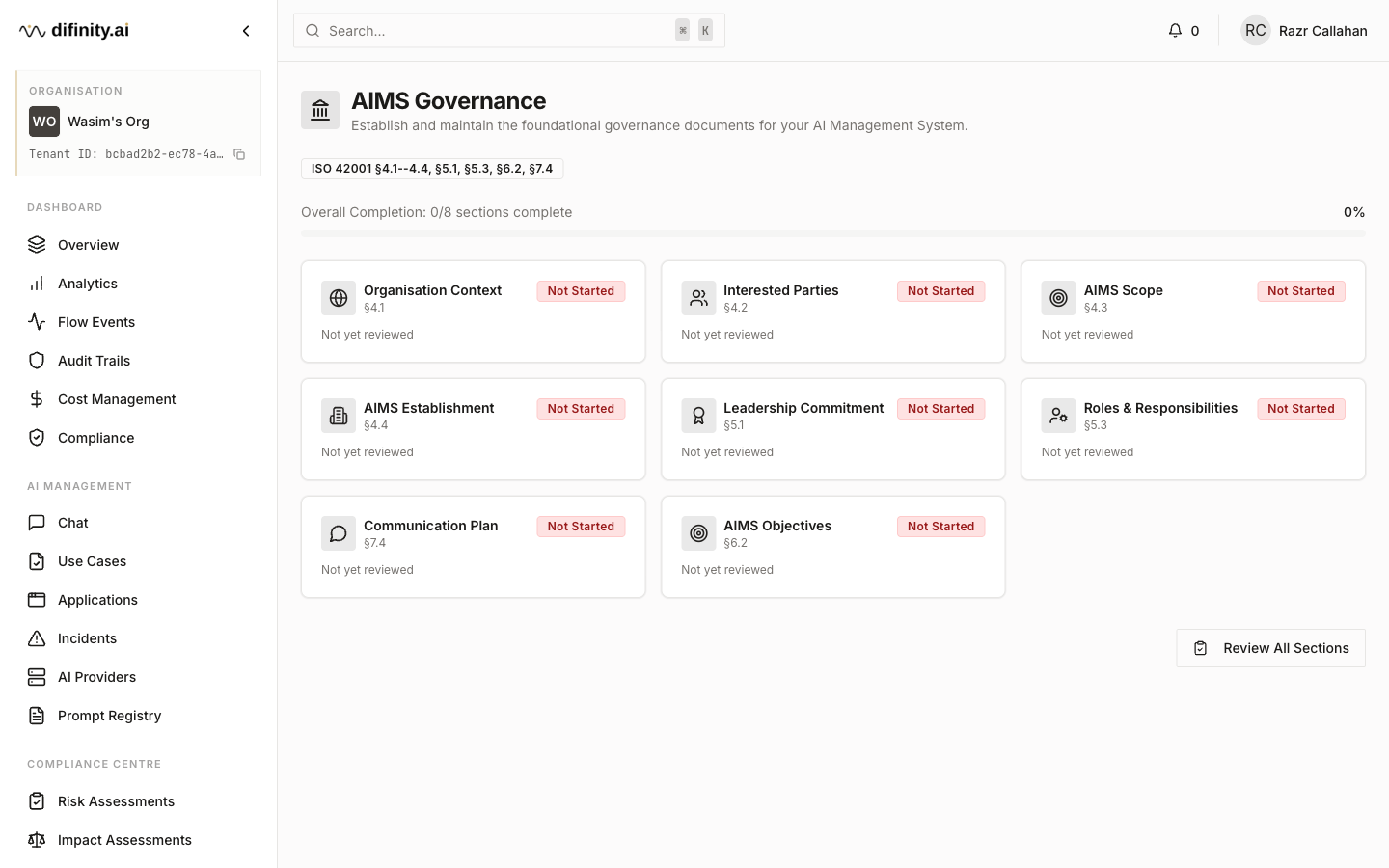
The AIMS Governance hub supports implementation of an AI Management System per ISO 42001. It is organised across five tabs aligned to the standard's structure:
| Tab | Clause |
|---|---|
| Context and Scope | Clause 4 |
| Leadership | Clause 5 |
| Support Resources | Clause 7 |
| Operational Controls | Clause 8 |
| Performance | Clauses 9–10 |
AI Policies
AI Policies supports the definition, versioning, and lifecycle management of AI policies and procedures as required by ISO 42001 §5.2.
Status workflow: Draft → Under Review → Approved → Published → Retired
Each policy is versioned, with a full history of changes and approvals. Policies can be linked to specific AIMS governance clauses and use cases.
Data Governance
The Data Governance section provides a framework for managing the data used in AI systems, covering data sourcing, quality, lineage, and retention in the context of AI workloads.
Competence and Training
Competence and Training addresses ISO 42001 §7.2–7.3 and EU AI Act Art. 4 requirements for AI literacy and competency management. The module tracks training records, competency assessments, and awareness programmes across the organisation.
Summary cards show overall competence compliance percentage, requirements fully met, identified gaps, and imminently expiring certifications.
Governance Reviews
Governance Reviews supports internal audits and management reviews as required by ISO 42001 §9.2–9.3 and EU AI Act Art. 17. Scheduled reviews are tracked with findings, action items, and sign-off records.
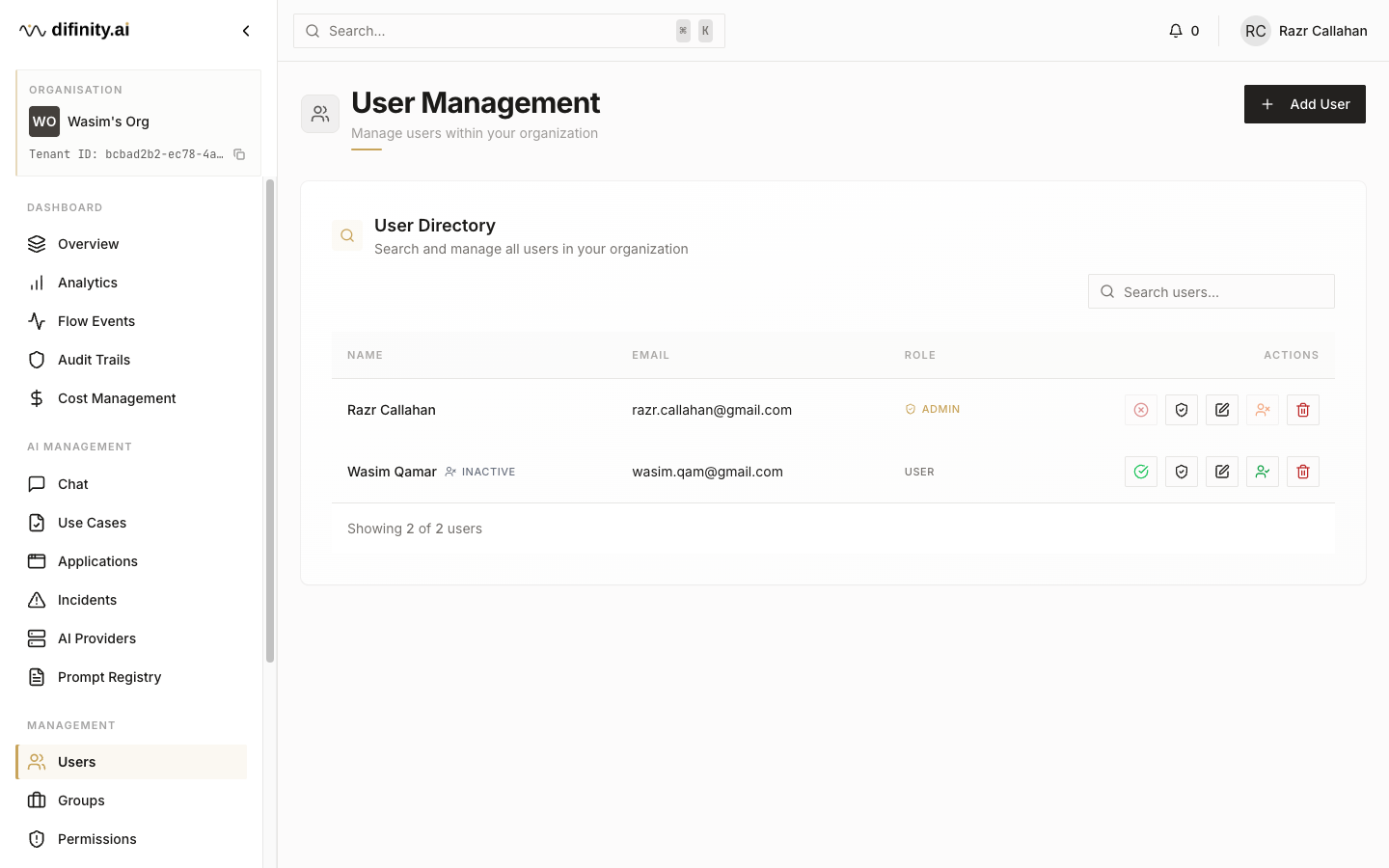
User Management
User Management covers the full identity and access model for Hub.
Users — add, edit, deactivate, and delete user accounts. Two base roles are available: Admin (full platform access) and Regular User (access governed by assigned permissions). New users are onboarded via email invitation.
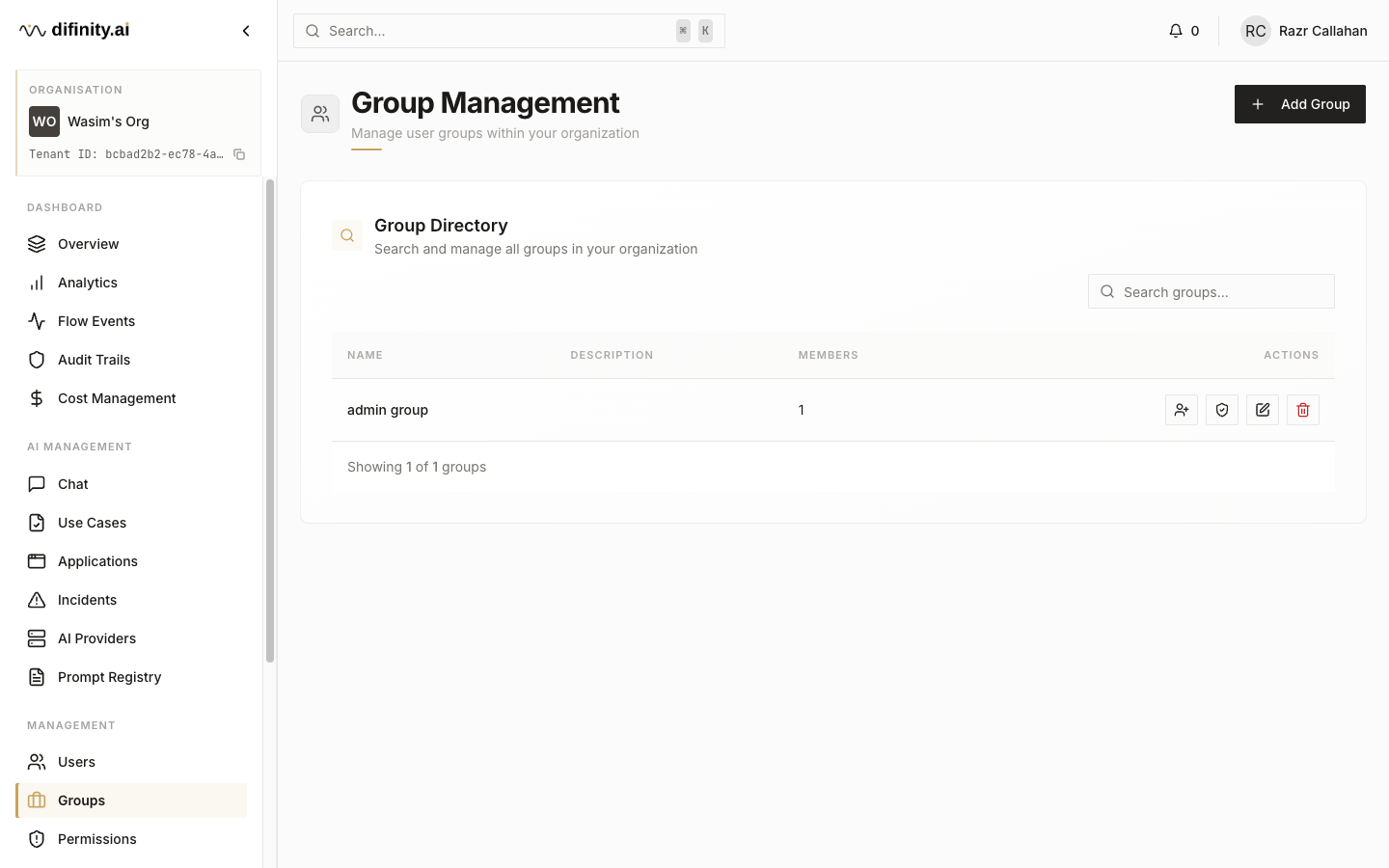
Groups — organise users into groups and assign permissions at the group level. Individual users inherit permissions from their groups, with the ability to extend at the user level.
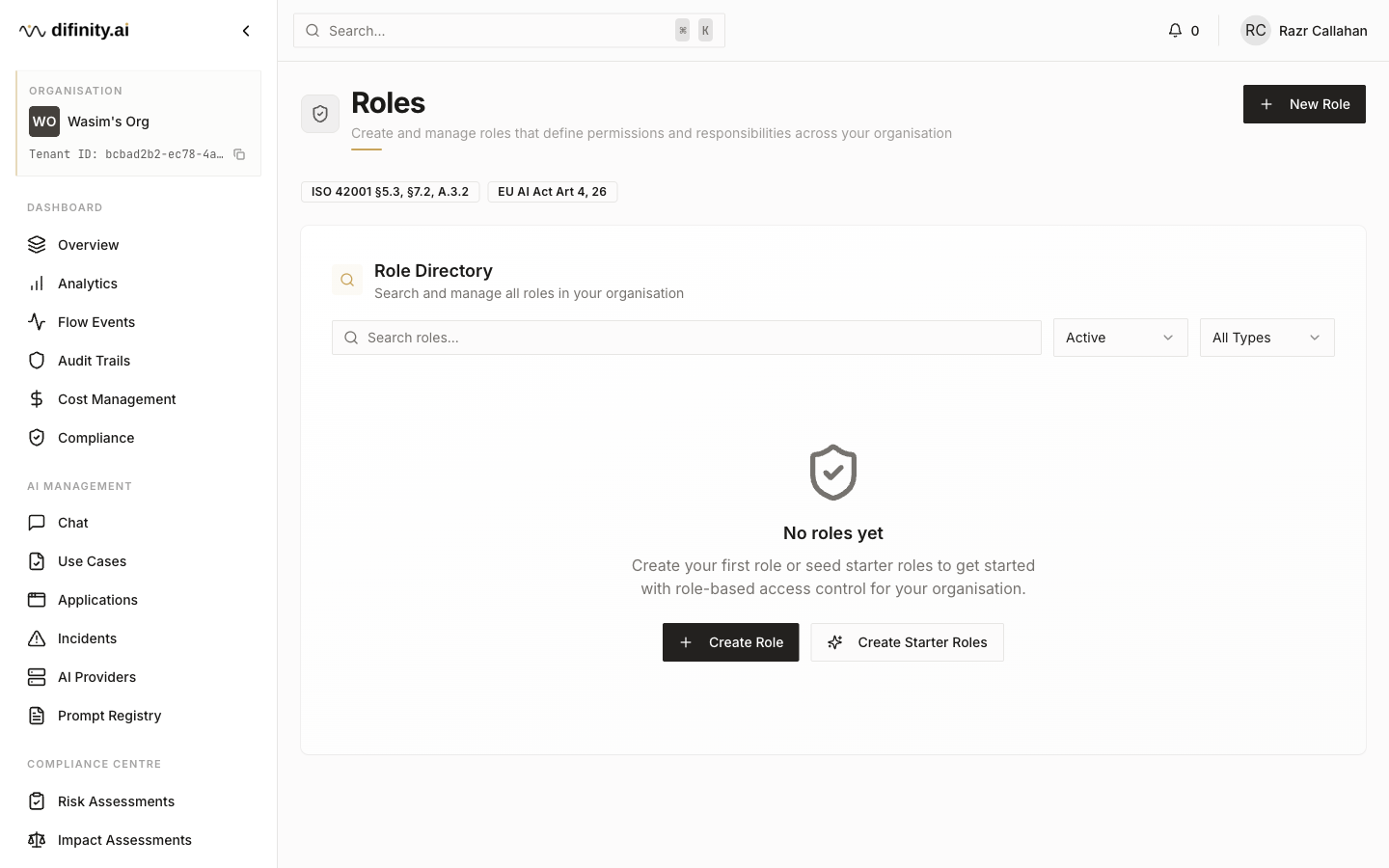
Roles — define role-based competency requirements aligned to Competence and Training tracking.
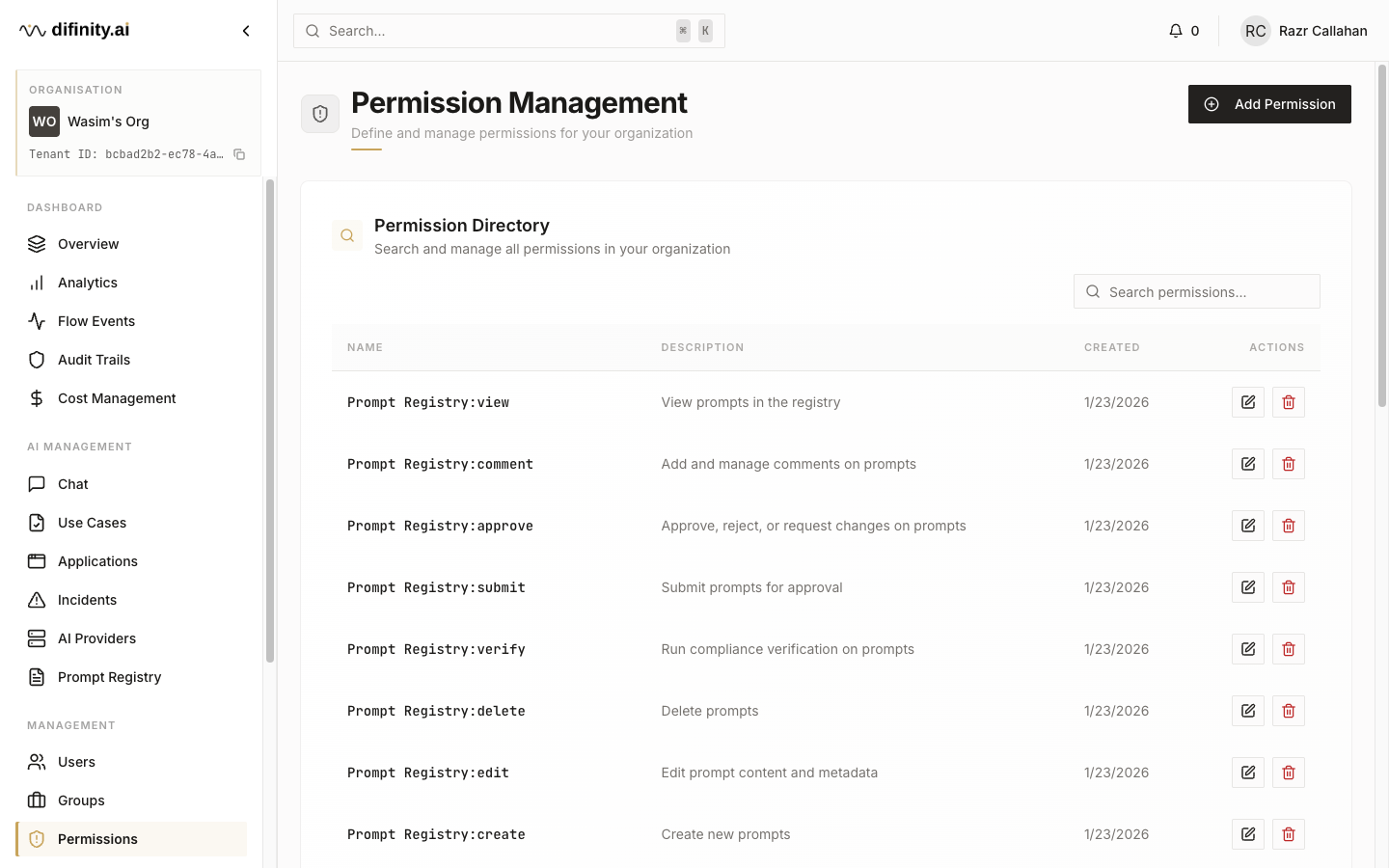
Permissions — granular per-feature access control with CRUD-level settings. Permission categories cover: Analytics, Audit Trails, Cost Management, Flow Events, Use Cases, Applications, Users, Groups, Chat, Incidents, Prompt Registry, and Compliance.
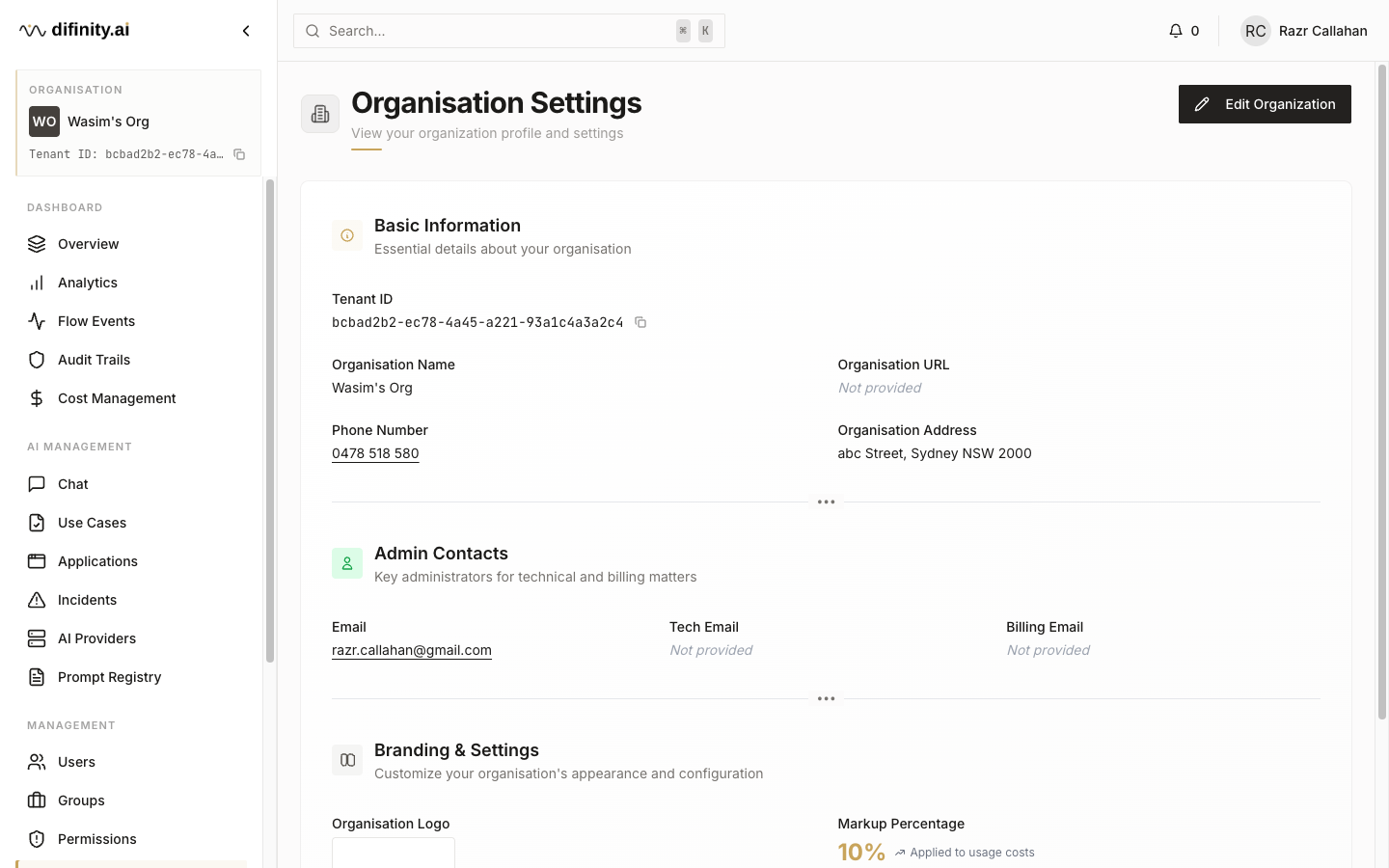
Organisation
Organisation settings configure tenant-level details: organisation name, contact information, technical admin email, markup percentage applied to provider costs, and default model configuration.
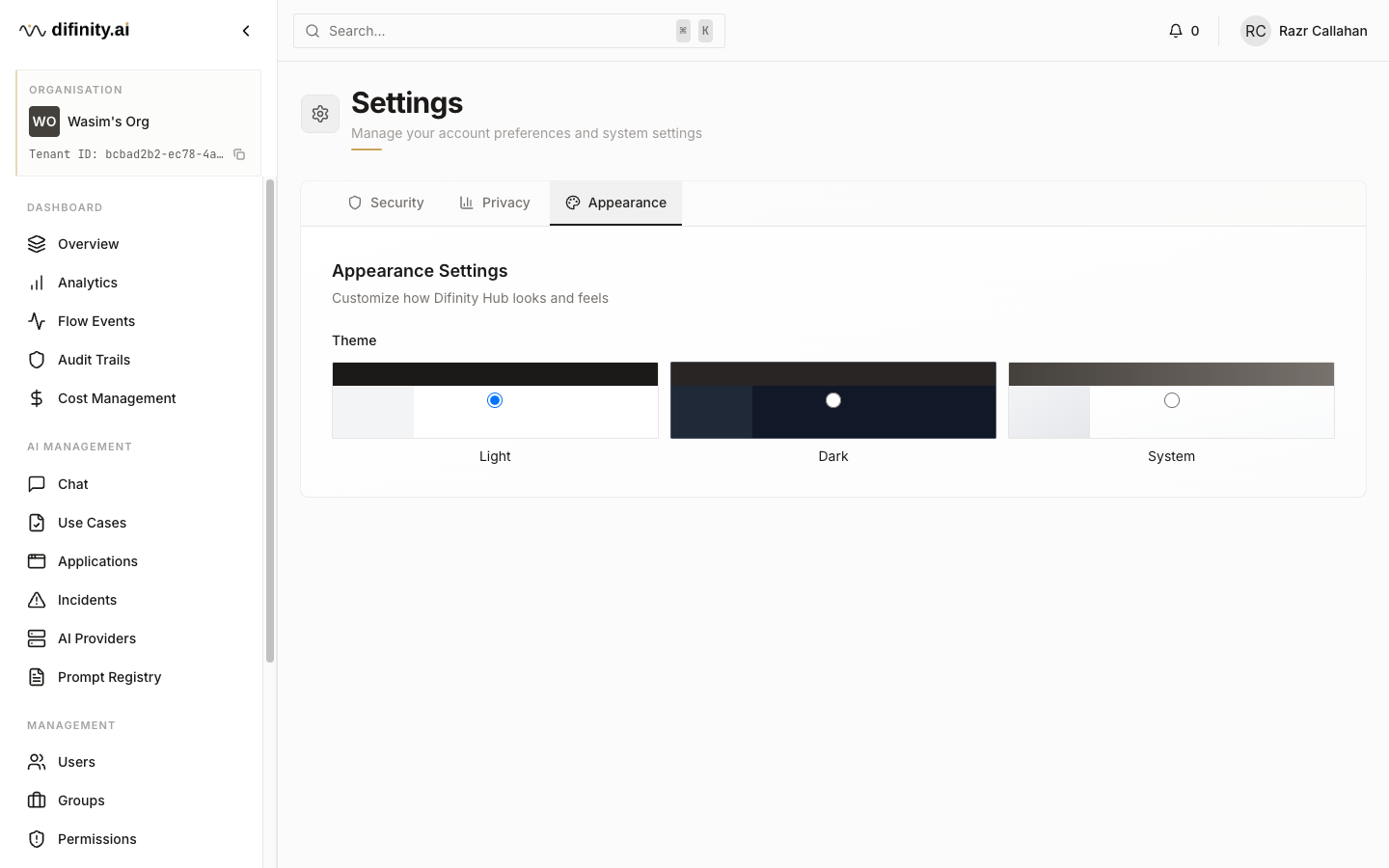
Settings
Personal settings cover appearance (light/dark theme), notification preferences, security (password, session management), privacy options, and localisation settings.
Difinity Flow API
Overview
The Flow API is the execution layer of the Difinity platform. It acts as a unified AI gateway, providing:
- A single authenticated entry point for requests to OpenAI, Anthropic, Google/Gemini, DeepSeek, Grok, and Meta.
- Provider-compatible endpoints that work as drop-in replacements for existing integrations.
- Built-in PII protection, content evaluation, and audit logging on every request.
- Intelligent routing via the
automodel selector. - Streaming support via Server-Sent Events.
- AI transparency metadata in all responses.
All endpoints enforce the compliance rules, PII settings, and access controls configured in Difinity Hub for the specified use case.
Authentication
Authentication to Flow API is a two-step process.
Step 1: Obtain a Hub API token
Generate an API token for your registered application from the Applications page in Difinity Hub.
Step 2: Exchange for a Flow JWT
POST /api/v1/auth/exchange
Request:
{
"api_token": "your_hub_api_token_here"
}
Response:
{
"access_token": "eyJhbG...",
"token_type": "Bearer",
"expires_in": 3600,
"app_id": "app-123",
"app_name": "My Application",
"tenant_id": "tenant-456",
"business_unit": "Engineering",
"cost_unit": "AI-Research",
"available_use_cases": [
{
"id": "chat-completion",
"name": "Chat Completion",
"risk_level": "low",
"is_enabled": true
}
],
"rate_limit": {
"enabled": true,
"max_requests": 60,
"window_seconds": 60
}
}
Flow JWTs expire after 3600 seconds (1 hour). Cache the token and re-exchange when it expires rather than exchanging on every request.
Required headers for all API calls:
Authorization: Bearer <flow_jwt>
X-USE-CASE-ID: <use_case_id>
Content-Type: application/json
The X-USE-CASE-ID header determines which use case configuration (compliance rules, PII settings, routing strategy, permitted models) applies to the request. The use case must be in the available_use_cases list returned by the token exchange.
Generic Chat API
POST /api/v1/chat
The generic API uses a message (single object) and history_messages (array) structure — not a flat messages array. This format is consistent across all providers when using the generic endpoint.
Request:
{
"provider": "openai",
"model": "gpt-4",
"message": {
"role": "USER",
"content": "Hello, how can AI help with customer service?",
"content_type": "text"
},
"history_messages": [],
"parameters": {
"temperature": 0.7,
"max_tokens": 1000,
"top_p": null,
"top_k": null,
"presence_penalty": null,
"frequency_penalty": null,
"stop": null,
"seed": null
},
"tools": null,
"outputFormat": null,
"stream": false
}
Supported providers: openai, anthropic, google, meta, deepseek, grok
Message roles: SYSTEM, USER, ASSISTANT, TOOL
Content types: text, image_url, code, json
For multimodal messages, use a contents array instead of a single content string:
{
"role": "USER",
"contents": [
{"content_type": "text", "content": "What is in this image?"},
{"content_type": "image_url", "content": "https://example.com/image.png"}
]
}
Response:
{
"id": "chat-12345",
"content": "AI can significantly improve customer service by...",
"model": "gpt-4",
"usage": {
"promptTokens": 15,
"completionTokens": 150,
"totalTokens": 165,
"latencyMs": 1200
},
"finish_reason": "STOP",
"tool_calls": [],
"status": null,
"transparency": {
"model_provider": "openai",
"model_id": "gpt-4"
}
}
For streaming responses, set "stream": true and include Accept: text/event-stream (or Accept: application/x-ndjson) in the request headers.
Topic Extraction API
POST /api/v1/chat/topic
Extracts a topic or title from a conversation. Used internally to auto-generate conversation titles in Hub Chat. Available for use in applications that maintain conversation history.
Compliance Verification API
POST /api/v1/verify
Runs all configured guardrail checks (PII redaction, content moderation, keyword filtering, etc.) against the provided message and returns results. No LLM call is made and no audit event is published. This is the appropriate endpoint for pre-flight compliance checks during development and testing.
Request:
{
"message": {"role": "USER", "content": "Check this content for compliance"},
"history_messages": []
}
Response:
{
"overall_status": "passed",
"checks": {
"harmful_content": {"status": "passed", "reason": null, "probability": null, "threshold": null},
"toxic_content": {"status": "passed"},
"manipulative_behaviour": {"status": "passed"},
"insensitive_language": {"status": "passed"},
"social_scoring": {"status": "not_applied"},
"fact_checking": {"status": "not_applied"},
"fake_news": {"status": "passed"},
"phishing": {"status": "passed"},
"blacklisted_keywords": {"status": "passed"},
"disallowed_topics": {"status": "passed"},
"custom_ethical_rules": {"status": "not_applied"},
"human_escalation": {"status": "not_applied"}
},
"pii_redaction": {
"detected": true,
"entities_found": [
{
"type": "EMAIL",
"original_text": "john@example.com",
"redacted_as": "[EMAIL_1]"
}
],
"redaction_count": 1,
"mode": "redact"
},
"redacted_content": {
"message": "Check this content from [EMAIL_1] for compliance",
"history_messages": []
}
}
Compliance Audit API
POST /api/v1/audit
Identical to /verify in request and response format, but also publishes an audit event to Hub. Use this endpoint when you need compliance checking with a full audit trail for observability and analytics. The event appears in the Flow Events view in Hub.
Compliance LLM Generation API
17 dedicated endpoints for AI-assisted generation of compliance documentation and analysis. Each endpoint uses the LLM configured for the requesting use case to generate contextually relevant content.
| Endpoint | Purpose | Regulatory Reference |
|---|---|---|
POST /api/v1/compliance/generate-tech-doc-section |
Generate Technical Documentation section | Art. 11, Annex IV |
POST /api/v1/compliance/generate-monitoring-narrative |
Generate monitoring plan narrative | Art. 72 |
POST /api/v1/compliance/suggest-risk-mitigations |
Suggest risk mitigations for identified risks | Art. 9 |
POST /api/v1/compliance/generate-ifu-section |
Generate Instructions for Use section | Art. 13 |
POST /api/v1/compliance/fill-registration-fields |
Fill EU AI database registration fields | Art. 49/71 |
POST /api/v1/compliance/assess-fundamental-right |
Assess impact on a specific fundamental right | Art. 27 |
POST /api/v1/compliance/assess-risk-classification |
Assess EU AI Act risk classification | Art. 6, Annex III |
POST /api/v1/compliance/generate-risk-context |
Generate risk assessment context narrative | Art. 9 |
POST /api/v1/compliance/identify-risks |
Identify applicable risks from catalogue | Art. 9 |
POST /api/v1/compliance/assess-conformity-requirement |
Assess a specific conformity requirement | Annex VI |
POST /api/v1/compliance/generate-action-plan |
Generate ISO 42001 corrective action plan | ISO 42001 |
POST /api/v1/compliance/generate-aims-section |
Generate AIMS governance section content | ISO 42001 |
POST /api/v1/compliance/generate-ai-policy |
Generate AI policy document | ISO 42001 §5.2 |
POST /api/v1/compliance/generate-audit-report |
Generate internal audit report | ISO 42001 §9.2–9.3 |
POST /api/v1/compliance/suggest-audit-findings |
Suggest audit findings from evidence | ISO 42001 |
POST /api/v1/compliance/batch-generate |
Batch generate multiple fields in one call | Multiple |
POST /api/v1/compliance/generate-field-guidance |
Generate guidance for a specific field | Multiple |
Provider-Compatible Endpoints
These endpoints accept the native request format of each provider. Add the standard Difinity headers (Authorization, X-USE-CASE-ID) and all governance rules apply transparently. This allows existing integrations to route through Difinity with minimal code changes.
OpenAI Compatible
POST /openai/v1/chat/completions
Standard OpenAI Chat Completions format. Supports streaming.
curl -X POST https://api.difinity.ai/openai/v1/chat/completions \
-H "Authorization: Bearer $FLOW_JWT" \
-H "X-USE-CASE-ID: chat-completion" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"temperature": 0.7,
"max_tokens": 150,
"stream": false
}'
Anthropic Compatible
POST /anthropic/v1/messages
Standard Anthropic Messages format. Supports streaming.
curl -X POST https://api.difinity.ai/anthropic/v1/messages \
-H "Authorization: Bearer $FLOW_JWT" \
-H "X-USE-CASE-ID: chat-completion" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-3-5-sonnet-20241022",
"max_tokens": 150,
"system": "You are a helpful assistant.",
"messages": [{"role": "user", "content": "Hello!"}]
}'
Gemini Compatible
POST /gemini/v1/models/{model}:generateContent
POST /gemini/v1/models/{model}:streamGenerateContent
Standard Google Gemini format. Use the streaming endpoint for real-time output.
DeepSeek Compatible
POST /deepseek/chat/completions
OpenAI-compatible format. Supports streaming.
Grok Compatible
POST /grok/v1/chat/completions
OpenAI-compatible format. Supports streaming.
All provider-compatible endpoints enforce the same compliance rules, PII protection, and audit logging as the generic /api/v1/chat endpoint.
AI Transparency Headers
Chat responses include a transparency field in the JSON body identifying the model provider and model ID that processed the request. The same information is also returned as HTTP response headers. This supports auditability requirements and helps teams verify that routing decisions are operating as configured.
Streaming
All chat endpoints support streaming via Server-Sent Events. Set "stream": true in the request body and include Accept: text/event-stream in the request headers. Responses are delivered as a stream of events, allowing the client to begin rendering content before the full response is complete.
Integration Examples
JavaScript / TypeScript
// Step 1: Exchange Hub API token for Flow JWT
async function getFlowJWT(hubApiToken) {
const response = await fetch('https://api.difinity.ai/api/v1/auth/exchange', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({api_token: hubApiToken})
});
const data = await response.json();
return data.access_token;
}
// Step 2a: Generic API — uses message + history_messages format
async function chat(jwt, message, useCaseId) {
const response = await fetch('https://api.difinity.ai/api/v1/chat', {
method: 'POST',
headers: {
'Authorization': `Bearer ${jwt}`,
'X-USE-CASE-ID': useCaseId,
'Content-Type': 'application/json'
},
body: JSON.stringify({
provider: 'openai',
model: 'gpt-4',
message: {role: 'USER', content: message, content_type: 'text'},
history_messages: [],
parameters: {temperature: 0.7}
})
});
return await response.json();
}
// Step 2b: OpenAI-compatible endpoint — drop-in replacement
async function chatOpenAI(jwt, message, useCaseId) {
const response = await fetch('https://api.difinity.ai/openai/v1/chat/completions', {
method: 'POST',
headers: {
'Authorization': `Bearer ${jwt}`,
'X-USE-CASE-ID': useCaseId,
'Content-Type': 'application/json'
},
body: JSON.stringify({
model: 'gpt-4',
messages: [
{role: 'system', content: 'You are a helpful assistant.'},
{role: 'user', content: message}
],
temperature: 0.7
})
});
return await response.json();
}
Python
import requests
def exchange_token(hub_api_token: str) -> str:
response = requests.post(
'https://api.difinity.ai/api/v1/auth/exchange',
json={'api_token': hub_api_token}
)
response.raise_for_status()
return response.json()['access_token']
# Generic API — uses message + history_messages format
def chat(jwt: str, message: str, use_case_id: str, model: str = 'gpt-4') -> dict:
response = requests.post(
'https://api.difinity.ai/api/v1/chat',
headers={
'Authorization': f'Bearer {jwt}',
'X-USE-CASE-ID': use_case_id,
},
json={
'provider': 'openai',
'model': model,
'message': {'role': 'USER', 'content': message, 'content_type': 'text'},
'history_messages': [],
'parameters': {'temperature': 0.7}
}
)
response.raise_for_status()
return response.json()
# OpenAI-compatible endpoint — drop-in replacement
def chat_openai(jwt: str, message: str, use_case_id: str, model: str = 'gpt-4') -> dict:
response = requests.post(
'https://api.difinity.ai/openai/v1/chat/completions',
headers={
'Authorization': f'Bearer {jwt}',
'X-USE-CASE-ID': use_case_id,
},
json={
'model': model,
'messages': [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': message}
],
'temperature': 0.7
}
)
response.raise_for_status()
return response.json()
Kotlin
import okhttp3.MediaType.Companion.toMediaType
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.RequestBody.Companion.toRequestBody
import org.json.JSONObject
val client = OkHttpClient()
val json = "application/json".toMediaType()
fun exchangeToken(hubApiToken: String): String {
val body = JSONObject(mapOf("api_token" to hubApiToken))
.toString().toRequestBody(json)
val request = Request.Builder()
.url("https://api.difinity.ai/api/v1/auth/exchange")
.post(body)
.build()
client.newCall(request).execute().use { response ->
return JSONObject(response.body!!.string()).getString("access_token")
}
}
// Generic API — uses message + history_messages format
fun chat(jwt: String, message: String, useCaseId: String): JSONObject {
val messageObj = JSONObject(mapOf(
"role" to "USER",
"content" to message,
"content_type" to "text"
))
val body = JSONObject(mapOf(
"provider" to "openai",
"model" to "gpt-4",
"message" to messageObj,
"history_messages" to emptyList<Any>(),
"parameters" to mapOf("temperature" to 0.7)
)).toString().toRequestBody(json)
val request = Request.Builder()
.url("https://api.difinity.ai/api/v1/chat")
.post(body)
.header("Authorization", "Bearer $jwt")
.header("X-USE-CASE-ID", useCaseId)
.build()
client.newCall(request).execute().use { response ->
return JSONObject(response.body!!.string())
}
}
Advanced Features
PII Protection System
Difinity's PII protection layer automatically detects and redacts personal data before it reaches an AI provider, then safely restores it in the response when appropriate. Supported entity types include names, email addresses, phone numbers, national identifiers, and postal addresses.
Redaction uses stable placeholder tokens (e.g., [EMAIL_1]) that are maintained in a session-scoped cache, ensuring continuity across multi-turn conversations — the same entity is always mapped to the same placeholder within a session. All PII handling events are logged for audit purposes.
PII handling mode (redact, mask, or pass-through) and detection sensitivity are configurable per use case in Hub.
Intelligent Model Routing
Setting "model": "auto" in a request activates Difinity's BERT-based routing system (RouteLL-BERT), which selects the most appropriate model based on query complexity, requirements, and the routing strategy configured for the use case (Cost, Performance, or Accuracy). If automatic routing fails, the system falls back to a default model. Manual model selection remains available for workloads with specific provider or model requirements.
Content Evaluation Engine
Every request through Flow passes through a multi-stage evaluation pipeline that runs both before the LLM call (pre-processing) and after (post-processing). Twelve check categories are available:
| Category | Description |
|---|---|
| Harmful content | Detects requests for harmful or dangerous information |
| Toxic content | Identifies toxic or abusive language |
| Manipulative behaviour | Detects persuasion or manipulation attempts |
| Insensitive language | Flags potentially offensive or discriminatory content |
| Social scoring | Detects social credit or discriminatory scoring patterns |
| Fact checking | Identifies factual claims for verification |
| Fake news | Detects misinformation patterns |
| Phishing | Identifies phishing or credential harvesting attempts |
| Blacklisted keywords | Exact and fuzzy keyword matching against a configured list |
| Disallowed topics | Topic-level filtering against a configured exclusion list |
| Custom ethical rules | Organisation-defined ethical rules |
| Human escalation | Triggers routing to a human reviewer based on configured conditions |
Each check has a configurable threshold. Results include status, confidence score, and the threshold that was applied, all visible in the Flow Events detail view.
Tool Calling
The generic chat endpoint supports tool/function calling via the tools field, using a format compatible with OpenAI's function calling specification. Tool results can be passed back as messages with role TOOL.
Deployment Options
Cloud (Recommended)
AWS ECS Fargate with auto-scaling (1–10 instances, 70% CPU target), multi-AZ deployment, Application Load Balancer with SSL/TLS termination, CloudFormation infrastructure-as-code, and CloudWatch monitoring. This is the standard deployment for most enterprise customers.
On-Premise
Docker container deployment within your own infrastructure. Supports air-gapped environments, custom security policies, and local model execution for data residency requirements.
Hybrid
Cloud-hosted API gateway with on-premise processing for sensitive workloads. Suitable for organisations with partial data residency requirements or staged cloud migration plans.
Infrastructure Requirements
| Tier | Specification |
|---|---|
| Minimum | 4 vCPUs, 16 GB RAM, 100 GB storage, SSL certificates, Docker |
| Production | Application Load Balancer, PostgreSQL HA, monitoring stack, automated backups, multi-AZ |
Troubleshooting
401 Unauthorized
- The Hub API token is invalid or has been revoked — verify in the Applications page.
- The Flow JWT has expired — JWTs are valid for 1 hour; re-exchange to obtain a new one.
- The
Authorization: Bearerheader is missing or malformed.
400 Bad Request
- The
X-USE-CASE-IDheader is absent. - The request body is malformed or missing required fields.
403 Forbidden
- The use case is not assigned to the application whose token was used.
- The use case is disabled or in Sandbox mode.
- Check the
available_use_casesarray in the token exchange response to confirm which use cases the token can access.
Slow Responses
- Check model availability in the AI Providers section of Hub.
- Enable streaming to reduce perceived latency for long-form responses.
- Review the Performance tab in Analytics to identify provider-level latency patterns.
Content Filtered
- Review compliance check thresholds in the use case's Responsible AI and Content Filtration configuration tabs.
- Use
/api/v1/verifyto inspect exactly which checks are failing and why before making changes. - Check for blacklisted keywords or disallowed topics that may be matching unintended content.
Health Check
curl https://api.difinity.ai/health
Rate Limits
| Endpoint | Limit |
|---|---|
| Token Exchange | 100 requests/minute/tenant |
| Chat API | 1,000 requests/minute/tenant |
| Streaming | 100 concurrent streams/tenant |
Best Practices
- Cache Flow JWTs — tokens are valid for 1 hour. Reuse them rather than exchanging on every request.
- Implement retry logic — use exponential backoff for transient failures.
- Use streaming for long-form content — reduces time-to-first-token and improves perceived responsiveness.
- Organise workloads by use case — separate use cases for different risk profiles, compliance requirements, and routing strategies.
- Monitor through Hub Analytics — track usage, latency, and cost trends proactively.
- Pre-flight with
/verify— during development, use the verification endpoint to test compliance behaviour without generating audit events. - Use provider-compatible endpoints for migration — if migrating from an existing OpenAI or Anthropic integration, the compatible endpoints require only header changes and no request body modifications.
Difinity Enterprise AI Governance Platform — enabling confident AI adoption through complete control, comprehensive compliance, and intelligent optimisation.